{kind=link}
Quand les responsables RH deviennent des bâtisseurs

Aperçu de l'expérience: Les projets collaboratifs d’IA ont offert des perspectives profondes sur les capacités RH, allant bien au-delà du simple développement d’outils.
Focalisation sur le problème: Passer de l’analyse des sentiments à la cartographie des compétences a souligné l’importance de définir des objectifs clairs et atteignables.
Scepticisme face à l'IA: Les professionnels RH rencontrent d’importants défis concernant la responsabilité et la transparence des plateformes d’IA existantes.
Structure de l’outil: L’outil d’évaluation IA a mis l’accent sur la collaboration, permettant aux utilisateurs de confirmer ou de contester les retours générés par l’IA.
Tests d’adversité: Le développement réussi d’un outil nécessite des tests rigoureux avec des entrées variées afin de traiter efficacement les cas limites.
Les réunions étaient prévues pour durer une heure. Elles dépassaient presque toujours.
Ce n’est pas inhabituel lorsque l’on réunit plusieurs professionnels des RH pour discuter d’IA. Ce qui était inhabituel, c’était ce qu’on leur demandait de faire lors de cette discussion. Pas l’analyser, ni rédiger une tribune, mais bel et bien construire quelque chose.
À l’automne 2025, j’ai réuni ce que j’appelais des "cohortes de bâtisseurs" : un petit groupe de professionnels RH et d’opérations que j’avais identifiés comme étant déjà à la tâche, déjà à la frontière de ce que la profession RH pourrait accomplir avec l’IA.
L’hypothèse était simple. Les personnes les plus proches des problèmes sont les mieux placées pour construire les solutions. La question était de savoir si elles en étaient capables.
Au total, j’allais constituer quatre cohortes, et j’ai compris qu’il est plus facile à dire qu’à faire de définir des objectifs pour ces sessions. Finalement, la plupart des cohortes se sont essoufflées, peinant à concrétiser la vision initiale ou à s’accorder sur un objectif commun. Les agendas, la charge de travail, les exigences de nos métiers ont souvent mené à des conversations riches en idées, mais rarement transformées en réalisations concrètes.
Mais une cohorte s’est rassemblée et a effectivement tenu jusqu’au bout du mieux qu’elle pouvait. En réalité, plus on s’enfonce dans la démarche du "faites-le vous-même", plus il devient difficile de respecter une vision commune et de relever le défi technique.
Voici le récit de ce qui est né de ces sessions et je vous le propose comme étude de cas pour construire vos propres solutions.
La Cohorte




Ce n’étaient pas des sceptiques de l’IA qu’il fallait convaincre. C’étaient des praticiens qui avaient déjà parié sur ce moment. Ce que la cohorte leur offrait, c’était un espace structuré pour enfin arrêter d’adviser, et commencer à créer.
La première conversation honnête
La première session a mis en lumière un aspect rarement évoqué dans les commentaires RH publiés : à quel point ces professionnels sont frustrés par les outils censés faciliter leur travail.
Turnmeyer a donné le ton. Elle avait tenté d’obtenir de la documentation technique sur le fonctionnement de l’analyse de sentiments au sein de BambooHR, Paycom, et Gusto—non pas pour dénigrer ces outils, mais parce que son service juridique devait les comprendre avant d’approuver leur utilisation.
Ni les équipes commerciales ni les représentants légaux n’ont pu répondre à ses questions. Les fonctionnalités d’IA existaient. La responsabilité quant à leur fonctionnement non.
Gillies devait gérer des tensions similaires. En interne, des voix s’élevaient autour de l’impact environnemental de l’IA, et certains collègues voulaient tout simplement interdire l’utilisation d’outils IA par les employés. Gillies a résisté.
Interdire purement et simplement l'IA conduit à une utilisation clandestine et à un risque accru. Adopter l'IA avec des garde-fous est une meilleure approche.
Melina Gillies · Directrice des Ressources Humaines, Flex Networks
Ce qui est ressorti de cette première heure, c’est un diagnostic sur lequel le groupe a pu s’accorder. Les fonctionnalités IA intégrées aux plateformes RH d’entreprise étaient, comme le disait Gillies, « souvent basiques et manquent de fonctionnalités ».
Les outils qui fonctionnent réellement ont tendance à être sur-mesure — conçus pour des problèmes précis, des contextes spécifiques, des entreprises particulières. Turnmeyer voulait moins d’outils, pas plus, un refrain que j’entends souvent de la part de responsables RH et opérationnels. Elle s’imaginait un avenir où une IA compétente, alimentée par les bons documents, rendrait un HRIS inutile.
Ils se sont aussi confrontés à un sujet rarement abordé aussi directement : l’éthique du suivi des comportements. L’idée d’utiliser les taux de refus de réunion, les écarts de connexion au système, ou des horaires inhabituels comme indicateurs de désengagement a vite été mentionnée.
Mais ils ont aussi reconnu les limites de cette approche. Satterfield a souligné un risque auquel chaque outil d’engagement finit par être confronté : la lassitude face à l’inaction. Si on collecte des données sans agir visiblement, les employés cessent de faire confiance au système. Les données deviennent du bruit et l’outil devient du théâtre de l’IA.
Ils n’étaient pas prêts à créer un outil d’analyse de sentiment. C’était trop vaste, chargé de dilemmes éthiques, et trop risqué à mal exploiter. Ils ont donc changé de cap.
Trouver le bon problème
La deuxième session a commencé par un aveu honnête : la direction initiale était trop ambitieuse et trop floue.
« Je ne sais pas si ça mesure vraiment l’engagement, disait Turnmeyer, ou si ça ne fait que mesurer quelque chose qui nécessite une conversation. »
Cette distinction est plus importante qu’il n’y paraît. Beaucoup de technologies RH font l’erreur de voir la donnée comme un substitut à la conversation. Le groupe voulait utiliser l’IA pour mettre en lumière les moments où une conversation s’impose, puis en améliorer la qualité.
Satterfield a présenté l’idée qui allait devenir le pilier du projet. Lors d’un gel des embauches dans un précédent emploi, elle avait conçu une auto-évaluation des compétences pour son équipe acquisition de talents — une manière de cartographier ce que les gens étaient capables de faire par rapport à ce qu’ils voulaient réellement faire, créant ainsi une carte thermique qui rendait les décisions de redéploiement plus humaines et plus stratégiques.
Ce n’était pas alimenté par l’IA. C’était un formulaire Microsoft. Mais la logique sous-jacente était pertinente, le cas d’usage réel, et elle l’avait vu fonctionner.
« Les grands éditeurs tentent de faire cela, mais personne ne s’en sort vraiment bien à ce jour, et beaucoup d’entreprises n’ont pas de budget alloué à ce type de technologie en plus de leur HRIS principal », disait-elle.
Le groupe a saisi l’opportunité. Et s’ils développaient une version natif-IA ? Une version conversationnelle plutôt que clinique, tournée vers l’avenir plutôt que pilotée par la conformité, et accessible pour les professionnels RH sans être enfermée derrière des contrats d’entreprise ?
La façon dont les RH s’adressent aux RH à propos des RH est radicalement différente. C’est une vraie valeur, et la plupart des outils la manquent complètement.
Melina Gillies · Directrice des Ressources Humaines, Flex Networks
Fisher, à l’écoute du groupe discutant des options, a partagé une remarque qui a reconfiguré tout le potentiel du projet. Il avait connu les deux visages des RH : la version conformité avant tout, axée sur les cadres, transactionnelle, et le praticien plus rare, centré sur l’humain, qui s’adressait à lui « comme à quelqu’un de son côté ».
« Le langage de la seconde catégorie, disait-il, ne ressemblait jamais à un copier-coller d’un cadre datant de plusieurs décennies. C’était tout simplement agréable. »
Gillies a rebondi sur l’idée. Le différenciateur de leur outil, soutenait-elle, serait justement le ton et la structure. Et si l’outil pouvait reproduire la manière dont les professionnels RH se parlent vraiment entre eux lors d’une conférence, entre deux sessions, en toute intimité ? Et s’il comprenait "la maîtrise politique" non pas comme une case à cocher, mais comme une notion chargée, contestée, contextuelle, sur laquelle les professionnels expérimentés débattent ?
C’était la bonne voie : un outil d’évaluation pré-embauche conçu pour les responsables RH et acquisition de talents ayant besoin d’une méthode plus fiable pour évaluer les candidats recruteurs avant de les embaucher. Pas un test de personnalité ni un simple filtrage de CV, mais un diagnostic structuré et conversationnel, capable d’indiquer à un manager si la personne en face sait vraiment faire le métier. Un outil qui ressemble moins à une évaluation de performance et davantage à une discussion avec quelqu’un qui connaît le recrutement de l’intérieur.

Le déclic
À la troisième session, le groupe était plongé dans l’architecture de l’outil : quelles compétences évaluer, comment structurer selon les niveaux, comment prendre en compte l’écart entre ce que les gens disent savoir faire et ce qu’ils savent réellement accomplir.
La critique des modèles existants est venue de Gillies, qui a décrit le modèle de compétences SHRM comme « très traditionnel et très tourné vers le passé sur certains aspects. » Selon elle, la profession souffrait encore d’une « gueule de bois post-industrielle » — fondée sur la conformité, hiérarchique, pensée pour un monde qui disparaît déjà.
Leur outil devait s’orienter vers autre chose, non pas ce que les responsables RH devaient savoir, mais ce qu’ils devaient être capables de faire.
Êtes-vous prêt à avoir une conversation avec le PDG au sujet de sa performance ? Si ce n’est pas le cas, vous n’êtes pas un expert des conversations difficiles.
Erin Turnmeyer · VP des opérations RH
Turnmeyer avait un exemple révélateur. Elle avait récemment passé l’examen SPHR. Les choses qu’il lui demandait de connaître—statuts, définitions procédurales, règles de classification—étaient des éléments que n’importe quel professionnel RH compétent irait simplement consulter.
Les compétences difficiles n’étaient pas dans le contenu de la certification. Elles étaient plutôt du type : Pouvez-vous vous asseoir en face d’un PDG et lui dire quelque chose qu’il ne veut pas entendre ? Savez-vous défendre un salarié quand le cas business reste ambigu ? Apprendre par cœur les codes du travail ne répond pas à ces questions.
Fisher est allé plus loin. Après des années passées dans la conduite du changement, il avait constaté que la variable la plus prédictive de la capacité d’une organisation à traverser une transformation n’était pas une compétence spécifique. C’était la relation de la personne à l’ambiguïté.
Être capable de jauger à quel point quelqu’un est à l’aise dans l’inconfort—ou avec le rythme du changement en général—a un effet révélateur sur la capacité à fonctionner dans ce nouveau monde.
Tim Fisher · Responsable IA, Black and White Zebra
Puis est arrivée ce que le groupe appellerait plus tard « la recette secrète ».
Gillies a lancé une question. Et si l’outil intégrait une vérification croisée ? Si quelqu’un se disait expert en gestion de conflit, mais qu’à une question complémentaire en réponse libre, il décrivait des situations qui ne ressentaient rien de l’expertise, l’IA pourrait-elle le détecter ? Pourrait-elle indiquer, avec tact, qu’il y a peut-être une compétence à renforcer ici ?
« C’est le déclic, » dit Turnmeyer.
Satterfield a noté que toute personne ayant travaillé avec des inventaires de compétences a déjà observé différentes variantes du même problème. Les individus s’auto-évaluent souvent très différemment que ce que leur expérience véritable ou leur comportement laisseraient supposer.
La valeur de l’outil ne viendrait pas du simple enregistrement de ce que les gens croient d’eux-mêmes. Elle viendrait du calibrage—cette friction douce et informée par les données entre l’auto-perception et la compétence démontrée.
L’évaluation ne serait pas simplement un miroir. Ce serait davantage « miroir, miroir, dis-moi » que ce à quoi la plupart des gens sont habitués lors des évaluations en entreprise.
Les réalités de la construction
Rien de tout cela n’a été simple. Et le groupe le savait en s’engageant dans l’aventure.
Le défi majeur n’était pas technique. C’était la portée. Chaque session a généré dix nouvelles pistes, toutes pertinentes et toutes susceptibles d’engloutir tout le projet. Turnmeyer l’a souligné tôt et régulièrement.
« Assurez-vous que la première fonctionnalité soit excellente, afin d’éviter un élargissement du scope qui rendrait la création impossible, » a-t-elle dit.
Satterfield a partagé un principe directeur avec le groupe : la différence entre un Produit Minimum Viable (MVP) et un Produit Minimum de Valeur. Un produit viable fonctionne. Un produit de valeur donne envie d’y revenir.
Dans un marché saturé d’outils d’évaluation, une interface qui n’apporte pas immédiatement une valeur significative n’aura pas de seconde chance pour s’améliorer. Le critère ce n’est pas la fonctionnalité. C’est l’utilité.
Si le produit n’offre pas assez de valeur dès la première utilisation, il est probable que les utilisateurs ne reviendront jamais vérifier s’il s’est amélioré.
Kelly Satterfield · Leader RH et consultante
Il y avait aussi des défis très concrets que tous ceux qui ont déjà construit en dehors d’une équipe de développement connaissent : déploiement, infrastructure de paiement, intégration aux systèmes existants, fenêtres contextuelles qui se ferment au milieu d’une session et effacent des heures de travail productif.
Les premiers prototypes reflétaient le parcours central de l’outil. Un candidat pour un poste de recruteur télécharge son CV, l’outil en déduit un profil de compétences préliminaire, puis l’accompagne via une série de questions conversationnelles conçues pour calibrer et approfondir cette première lecture.
À la fin, le responsable du recrutement obtient une vision claire de la position réelle du candidat au regard d’un référentiel de compétences défini.
Fisher a mis en place l’environnement principal de développement sur Lovable—un constructeur IA no-code qui génère des outils publics à travers la conversation, sans enfermer les utilisateurs dans un LLM spécifique—afin que l’architecture technique puisse suivre le rythme des réflexions du groupe sans devenir un point de blocage.
Du plan à la construction
Dès la quatrième session, le groupe n’était plus en train de concevoir un outil abstrait. Il en construisait un, et découvrait—comme tous les constructeurs—que la véritable phase d’apprentissage se situe précisément dans l’écart entre l’idée et la réalisation.
Fisher avait assemblé un GPT personnalisé de base avant l’appel, chargé d’instructions, d’un cadre de compétences préliminaire et des débuts de la logique de conversation qu’ils avaient ébauchée lors de sessions précédentes. Le projet était que chacun y accède, le sollicite en équipe et commence à calibrer sa voix et son comportement en temps réel. Le projet s’est immédiatement heurté à la réalité.
Le lien partagé ne fonctionnait que pour moi. Les autorisations de l’espace de travail, les bizarreries de la plateforme et la façon particulière dont ChatGPT gère les accès externes ont englouti le premier quart de la session.
Ce fut une petite frustration, précisément du genre de celles qui n’apparaîtront jamais dans le communiqué d’un produit — et cela fut instructif. Les outils que les praticiens utilisent réellement pour créer des choses ne se comportent pas comme des démos.

Cette capture d’écran montre à quoi ressemblerait finalement l’écran d’accueil de l’outil développé par le groupe, appelé Talent Scout.
Une fois que tout le monde avait le même écran devant les yeux, il s’est passé quelque chose de plus intéressant. Alors même que le groupe discutait encore du format que devaient prendre les définitions de compétences, Gillies a ouvert Claude dans une autre fenêtre et a converti le tableau de notation en JSON structuré — en direct, pendant l’appel.
« J’utilise Claude parce qu’il est meilleur que ChatGPT pour ça, » dit-elle, sans chichis. Elle a ensuite déposé le fichier formaté dans le chat du groupe quelques minutes plus tard. Personne ne prit le temps de souligner l’exploit. Le groupe a simplement continué.
Ce genre de résolution de problème en mouvement — transformer un goulot d’étranglement en une solution sans en faire le sujet du meeting — distingue les praticiens ayant véritablement intégré ces outils, de ceux qui apprennent encore à les utiliser.
Qui a le dernier mot ?
Satterfield a soulevé une question qui aurait des implications majeures tant pour l’architecture de l’outil que pour son accueil final : est-ce l’IA qui rend la décision finale, ou l’utilisateur qui la confirme ?
La nuance n’est pas cosmétique. Si l’outil livre un verdict du type « Sur la base de vos réponses, vous êtes au niveau 2 en orientation candidat », alors l’IA se positionne comme autorité. Si, à l’inverse, il propose une interprétation provisoire et invite l’utilisateur à s’exprimer, la dynamique change complètement. L’évaluation devient collaborative plutôt qu’évaluative. L’utilisateur devient partie prenante du processus, et non objet de celui-ci.
« Acceptez-vous ce retour ? » dit Turnmeyer, à mesure que l’idée faisait son chemin. « J’adore l’idée. »
Gillies a construit la logique. Si l’utilisateur n’accepte pas la notation, l’outil demande ce qui ne lui semble pas correct — puis utilise cette réponse pour recalibrer ou, au contraire, reconfirmer doucement son interprétation en passant en revue les éléments.
Ce va-et-vient conversationnel est précisément ce qui crée la sécurité psychologique dont l’outil a besoin pour être réellement utile. Les gens ne changent pas s’ils ne font pas confiance aux retours qu’ils reçoivent. Obtenir l’adhésion n’est pas une caractéristique accessoire : c’est le cœur du mécanisme.
La première véritable mise à l’épreuve
Ils décidèrent de tester le prototype en direct. Turnmeyer s’est portée volontaire pour donner une réponse volontairement superficielle à l’une des questions de l’évaluation — du genre que donnerait un candidat peu investi ou un salarié distrait.
Elle décrivait une dispute avec son responsable au sujet d’un différentiel de salaire, la perte du candidat, et ignorait totalement ce qu’était devenu le dossier. C’était l’équivalent RH de répondre « J’aime simplement les gens » à la question « Pourquoi voulez-vous travailler en RH ? »
L’outil a évalué la réponse immédiatement. Il lui a attribué un niveau. Il était encourageant. Il s’est aussi trompé : pas factuellement, mais prématurément. Il avait fait des suppositions sur le sens de la réponse au lieu de demander le contexte nécessaire pour une évaluation pertinente.
Si vous donnez à quelqu’un une évaluation autre que « répond aux attentes », vous devez fournir des exemples détaillés. L’IA devrait être tenue à la même exigence.
Erin Turnmeyer · VP People Operations
Turnmeyer a tiré ce parallèle directement de sa pratique de l’évaluation de la performance. Elle exigeait depuis longtemps des managers qu’ils fournissent des éléments précis avant d’attribuer une note supérieure ou inférieure à « répond aux attentes ».
La même rigueur doit s’appliquer à l’outil. Avant d’assigner un niveau, il doit mériter ce droit en posant les questions qui rendront l’évaluation défendable. Là encore, c’est l’expertise RH présente autour de la table qui améliore l’IA, jamais l’inverse.
Satterfield a ajouté une difficulté que l’outil avait négligée. La réponse superficielle pouvait refléter une politique, et non un manque de compétence.
Si le manager avait effectivement fixé une limite stricte sur la rémunération, argumenter davantage n’aurait rien changé à l’issue. L’outil avait évalué la personne alors qu’il aurait dû interroger la situation. Les questions de clarification ne sont pas un détail cosmétique : elles font la différence entre une évaluation utile et une évaluation présomptueuse.
Turnmeyer a pris comme devoir de rédiger des instructions : comment inciter un outil à poser des questions de clarification au bon moment sans transformer chaque interaction en interrogatoire ?
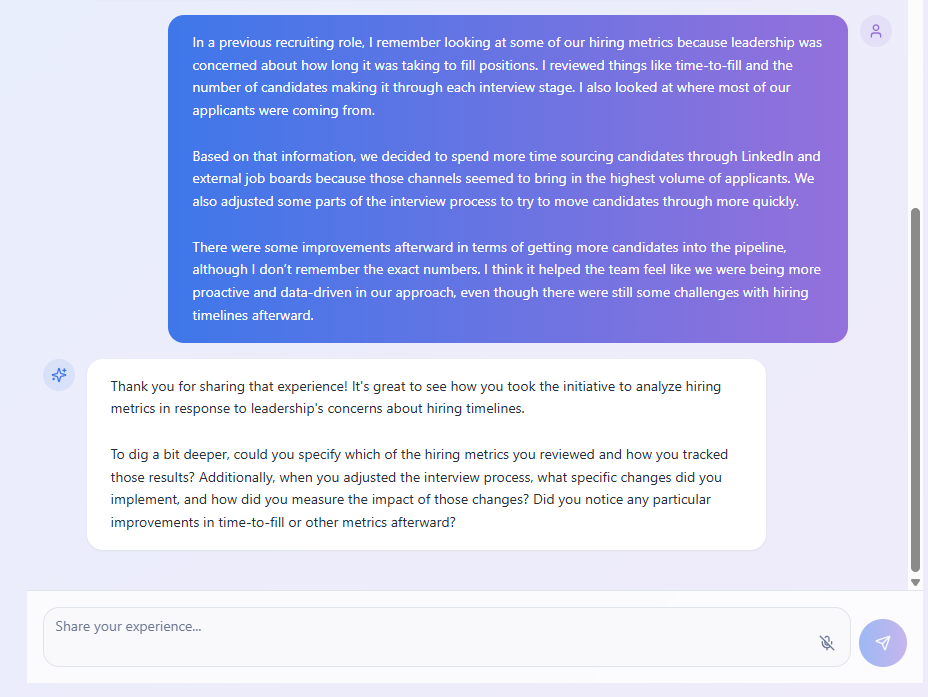
Cette capture d'écran illustre un exemple de ce que le produit final réaliserait : poser des questions de clarification et inciter le candidat à approfondir ses réponses.
C'est un problème plus complexe qu'il n'y paraît, et elle était pleinement consciente que le niveau d'exigence était exceptionnellement élevé.
« Il faut que ce soit meilleur qu'un humain, » a-t-elle déclaré. « C'est la norme. »
Les tests comme discipline
La session a également permis de faire émerger l’un des enseignements méthodologiques les plus pratiques de tout le groupe. Lorsque Satterfield a demandé comment le groupe testait habituellement des outils de ce type, tant Turnmeyer que Gillies ont apporté des réponses qui ont mis en lumière un aspect clé de ce à quoi ressemble réellement un test rigoureux en pratique.
Pour son outil de recommandations d’avantages sociaux, qui devait indiquer avec précision si des médicaments spécifiques étaient couverts par le régime de santé de l’entreprise, Turnmeyer a testé précisément les cas limites. Pas les médicaments évidents, ni les plus courants que le modèle aurait croisés maintes fois à l’entraînement. Elle s’est concentrée sur les plus obscurs, dans les catégories les plus susceptibles de générer une hallucination confiante.
« Je suis allée tester les médicaments peu courants », dit-elle, « parce que Claude m’a montré ce qu’il faisait quand il le concevait. »
Ce niveau d’intentionalité contradictoire dans les tests est rare lorsque les créateurs ne viennent pas d’un contexte ingénieur. C’est aussi exactement ce qui différencie les outils qui gagnent la confiance de ceux qui sont discrètement abandonnés après un échec embarrassant.
Élaguer ce que vous avez déjà construit
Une session de regroupement juste avant les vacances a débuté par une question plus complexe à poser qu’il n’y paraît : à quoi sert réellement la fonctionnalité d’import de CV ?
Gillies l’a soulevée. L’évaluation demandait aux utilisateurs de réfléchir attentivement à leurs propres compétences. Le CV ajoutait-il des informations que l’utilisateur n’aurait pas pu fournir plus directement en répondant simplement aux questions ? Personne dans le groupe ne pensait que oui. L’intention initiale était de gagner du temps, comme un parseur de CV, mais nous n’étions plus convaincus que cela répondait à cet objectif.
Ils ont convenu de la supprimer.
Cela est plus rare qu’il n’y paraît dans le développement produit. Le groupe avait passé du temps réel sur la fonction d’import—la construire, la tester, observer le CV de Satterfield être analysé et mal noté. La supprimer a nécessité de dépasser le biais du coût irrécupérable qui pousse les équipes à ajouter sans cesse à ce dans quoi elles ont déjà investi.
Commencez avec l’objectif final en tête, et définissez à quoi ressemble un bon résultat. Si vous ne pouvez pas expliquer l’intérêt d’une fonctionnalité, alors vous ne pouvez pas la justifier.
Turnmeyer a émis un autre argument, lié à la méthodologie. Avec le recul, elle pense qu’ils auraient pu avancer plus vite en définissant entièrement le comportement de l’outil avant d’écrire la moindre instruction. Ils avaient adopté une sorte de modèle agile—construire, tester, ajuster—alors que la complexité de ce qu’ils construisaient aurait peut-être exigé une méthode plus en cascade : définir le cahier des charges d’abord, puis s’y tenir pour le développement.
Elle disposait d’un cahier des charges de 130 pages pour un outil différent, qui lui avait appris cette leçon. Un cahier des charges complet ne sert pas seulement à indiquer ce qu’il faut construire. Il précise aussi ce qu’on ne construit pas, ce qui s’avère tout aussi utile.
Gillies a recentré le problème central du produit. Quoi que l’outil affiche à l’écran, cela devait aller plus loin. Un diagnostic qui expose des données n’est pas la même chose qu’un outil qui vous indique quoi en faire. Cet écart entre la sortie et l’action est exactement là où les outils de diagnostic cessent discrètement d’être utiles, et c’est le fossé que la plupart d’entre eux ne comblent jamais.
Construire seul
En janvier, Satterfield faisait l’essentiel du développement elle-même, le reste du groupe étant happé par leurs emplois à plein temps, ce qui ne laissait plus de temps pour le projet. Après tout, personne n’était rémunéré pour ça.
Elle avait supprimé l’import de CV, comme convenu avec le groupe. Elle avait ajouté la saisie vocale—les utilisateurs pouvaient désormais répondre aux questions de l’évaluation à l’oral plutôt qu’à l’écrit, ce qui ouvrait une manière plus conversationnelle de répondre, moins facile à biaiser qu’un champ texte.
Elle utilisait ChatGPT pour générer des réponses de test synthétiques (« Je suis un recruteur junior, je suis fort là-dessus et faible là-dessus, donne-moi des réponses »), puis basculait sur Lovable pour saisir ces réponses et observer la façon dont l’outil les notait.
Le tableau de bord des leaders était l'autre moitié de la logique de l’outil — la vue qu’un directeur de recrutement ou un CHRO utiliserait pour voir comment un candidat avait été noté, où se trouvaient les écarts, et comment ses compétences pourraient compléter les forces et les besoins d’une équipe existante.
Cela rendait la structure organisationnelle réellement problématique, car l’outil devait savoir qui évaluait qui et qui avait l’autorité de voir les résultats.
Satterfield avait tenté de gérer cela en demandant aux utilisateurs de saisir leur nom, leur poste et le nom de leur responsable (en l'absence d'intégration de données). Mais cette logique s’est brisée dans un scénario courant : un directeur du recrutement qui voulait envoyer l’évaluation à une organisation de recrutement plus large comprenant à la fois des relations hiérarchiques directes et indirectes. La logique de cartographie de l’organisation n’était pas assez nuancée pour prendre en compte cette structure.
En théorie, ces informations devaient donner à l’outil un meilleur contexte sur le rôle de l’évalué, mais collecter davantage de données compliquait les choses.
Turnmeyer avait déjà résolu une version de ce problème dans un autre contexte. L’outil de gestion de la performance qu’elle avait conçu pour sa propre entreprise fonctionnait sur Google Sheets, Slack et Claude. Google Sheets stockait les données. Slack était l’interface avec laquelle les employés interagissaient. Claude gérait l’analyse et la génération des retours.
L’architecture était plus simple qu’elle n’y paraissait : une feuille de calcul avec le nom, l’email, le niveau de poste et le titre du poste. Un onglet séparé faisant le lien entre le niveau de poste et les compétences.
« La sécurité dans mon entreprise voulait examiner mon outil », raconta-t-elle au groupe. « J’ai dit qu’il était stocké dans Google Docs. Ils ont réagi : ‘Ah, c’est tout simple.’ »
Simple, mais Turnmeyer ne l’a découvert qu’en construisant. Ce qu’elle ne savait pas trois semaines auparavant, c’est que le journal existait — une fonction qui sauvegarde la progression d’un utilisateur afin que l’outil ne se réinitialise pas quand quelqu’un s’absente puis revient.
Je jurais après Claude », dit-elle, « jusqu’à ce qu’il m’indique que le journal existait.
C’est ce que l’on apprend en construisant. Pas la chose que l’on prévoyait d’apprendre, mais celle qu’on ne savait pas devoir connaître.
More Articles
La question sous-jacente
À un moment durant la session de janvier, la conversation a abouti à la question qu’elle tournait autour depuis des mois.
Le groupe n’arrêtait pas de discuter architecture, autorisations, stockage, tableaux de bord — tous des problèmes réels. Mais en dessous se trouvait une question plus fondamentale : qu’essayaient-ils vraiment de construire, et pour qui ?
L’outil, tel qu’il avait été conçu à l’origine, était un diagnostic de sélection — quelque chose qu’un responsable de recrutement pouvait envoyer à un candidat ou à un collaborateur interne pour évaluer si ses compétences réelles correspondaient à son CV, et obtenir ce portrait avant de prendre une décision de recrutement.
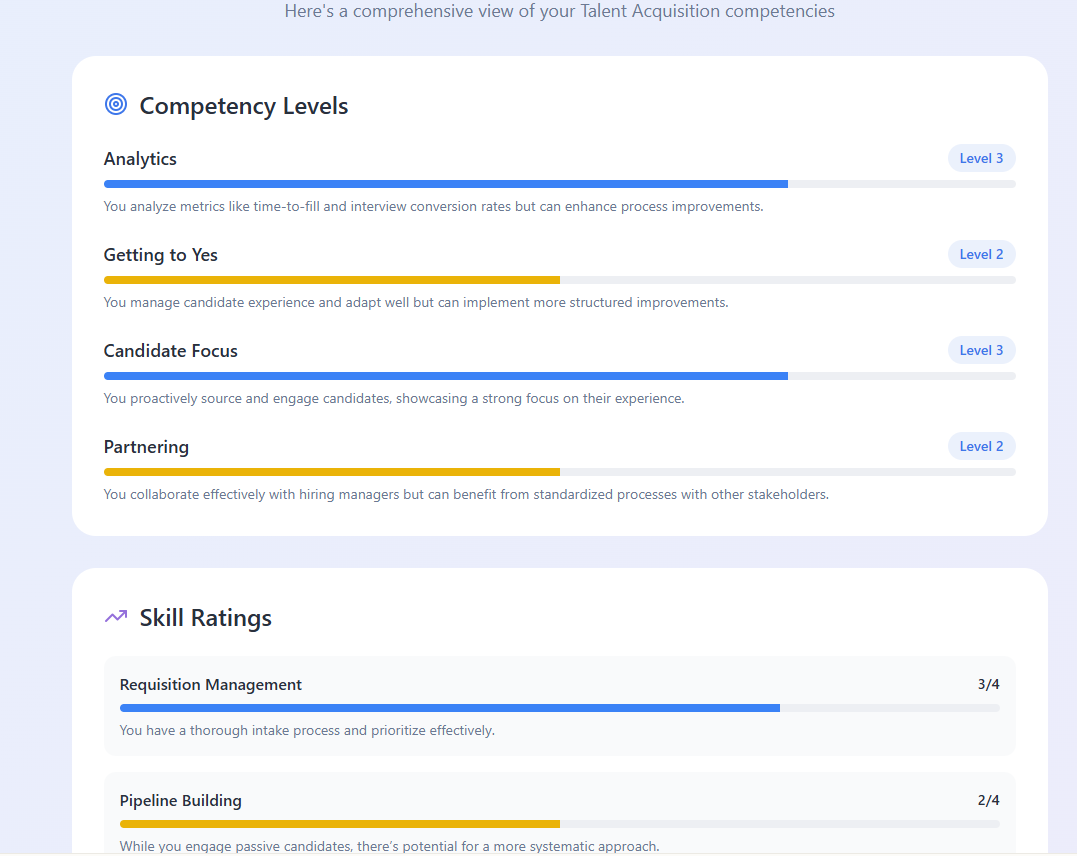
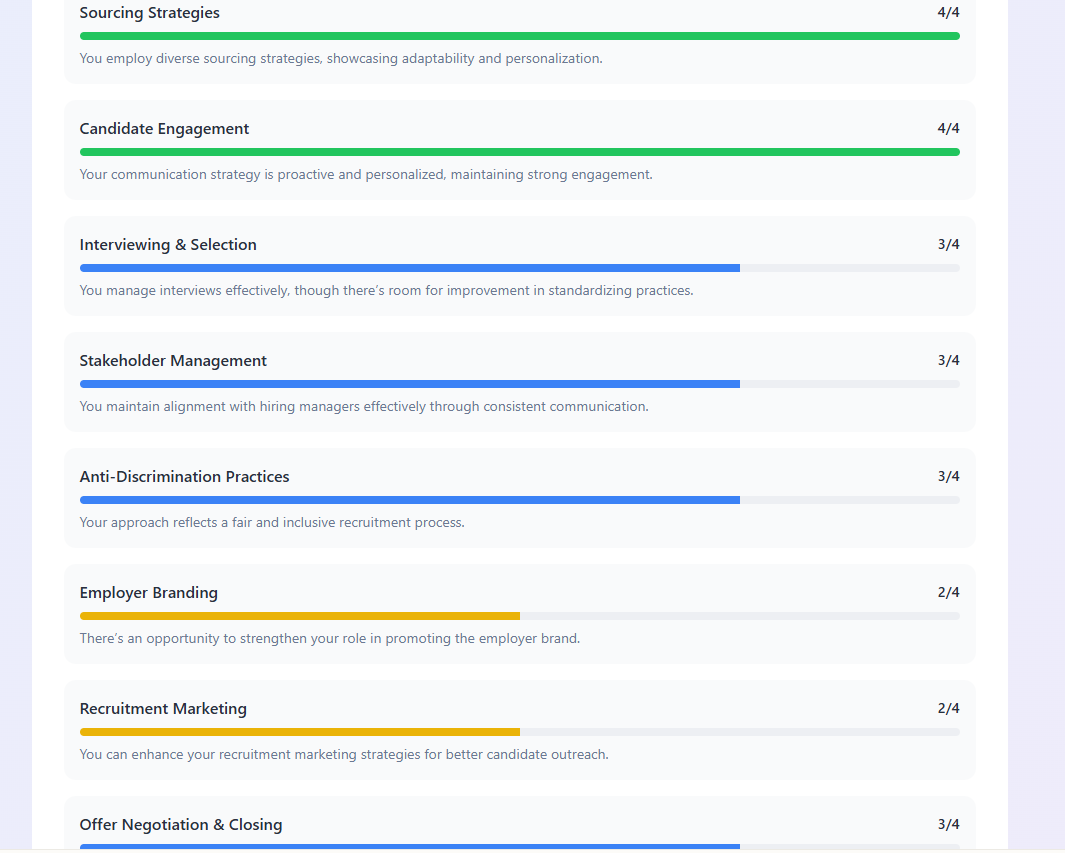

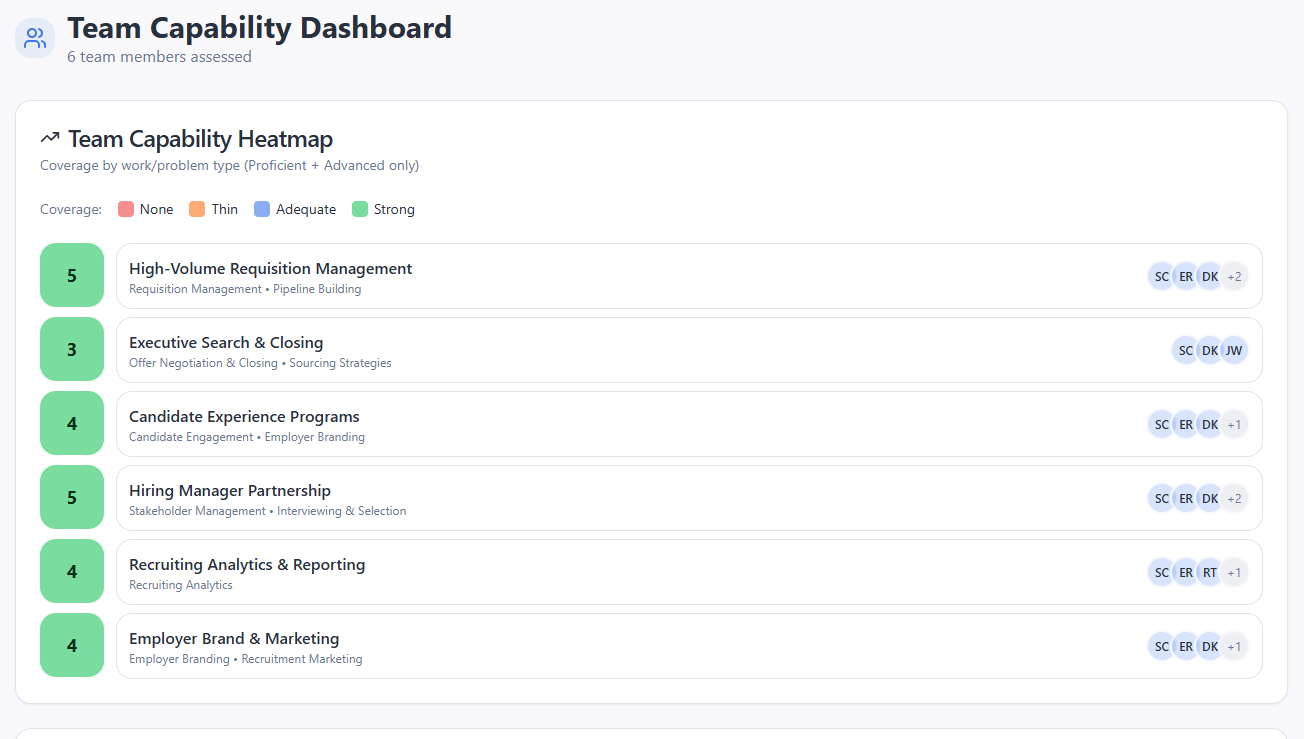
Ce que vous voyez ici est une sélection de captures d'écran du type de rapport que l’outil produisait pour l’interviewé. Pour l’évaluateur, un tableau de bord des forces actuelles de l’équipe l’aide à se concentrer sur les points à vérifier chez l’interviewé afin de voir s’il répond aux faiblesses de l’équipe TA.
Ce cœur n’avait pas changé. Mais chaque décision pratique prise — ajouter un tableau de bord leader, réfléchir aux modèles d’abonnement, travailler sur un flux de connexion — les poussait vers quelque chose de plus complexe.
Des tableaux de bord en temps réel signifiaient un accès continu, ce qui impliquait des frais d’abonnement, ce qui rapprochait du type d’outils d’entreprise que de nombreuses organisations ont du mal à s’offrir ou à mettre en œuvre efficacement.
« On ne cherche pas à devenir un fournisseur HCM », a dit Satterfield.
Turnmeyer était honnête sur sa position.
« Mon intention était simplement d’apprendre quelque chose de nouveau. »
Ce n’était pas un désengagement du projet. C’était un constat fidèle de ce que l’expérience lui avait déjà apporté. Elle avait appris de nouvelles choses et était déjà en train de concevoir un nouvel outil de gestion de la performance en appliquant les enseignements du groupe.
Elle n’avait pas besoin de transformer l’outil du groupe en produit pour en retirer une vraie valeur.
À ce stade, mon propre intérêt était surtout éditorial. Je voulais une histoire à raconter et quelque chose à montrer, pas un produit par abonnement, mais une démonstration que les professionnels RH pouvaient envisager — et peut-être reproduire.
Rédiger cet article en faisait partie. Pourrais-je créer un guide à télécharger ? Éventuellement, un événement en direct où le groupe pourrait discuter de ce qu’il avait réalisé, permettre à une audience d’interagir avec l’outil, et enregistrer la conversation en podcast ? J’avais beaucoup d’idées, mais le temps disponible pour les concrétiser se réduisait alors que les objectifs de la nouvelle année s’accumulaient devant nous.
L’intérêt de Satterfield était le plus orienté business, et elle l’a clairement exprimé. Elle souhaitait en faire un produit à terme. Elle n’allait pas s’en charger seule. Mais elle était prête à continuer à avancer vers quelque chose qui pourrait, un jour, être vendu.
Cette divergence à trois sens de l’intention—apprentissage, narration, produit—est probablement inhérente à toute cohorte de ce type. La discussion honnête qui a eu lieu en janvier a été bien plus utile que de faire semblant que tout le monde avait toujours voulu la même chose.
La démo comme réponse
La question de savoir comment laisser les gens essayer l’outil n’était toujours pas résolue depuis la mise en ligne du dépôt de CV. Tester avec de vrais utilisateurs est précieux, mais cela engendre ses propres problèmes. L’outil doit fonctionner de façon fiable, les utilisateurs doivent avoir suffisamment de contexte pour comprendre ce qu’ils font, et une mauvaise première expérience est difficile à rattraper.
Turnmeyer a proposé la solution la plus simple qu’ait envisagée le groupe.
Elle avait regardé des enregistrements de démos—de courtes démonstrations d’une minute ou deux, montrant comment fonctionne un outil sans que le spectateur ait réellement à l’utiliser. Elle a suggéré que cela pouvait suffire. Les gens pouvaient voir l’outil en action, comprendre ce qu’il faisait et pourquoi, et repartir en ayant l’impression que c’était envisageable.
Ils n’auraient ni à se connecter, ni à fournir un organigramme, ni à se retrouver bloqués si une question d’évaluation ne correspondait pas à leur situation.
Le retour que je reçois souvent sur mes articles de blogs, c’est que les gens ne veulent pas vraiment copier-coller exactement la même chose. Ils veulent seulement savoir qu’ils sont capables de le faire.
Erin Turnmeyer · VP des Opérations RH
Cette observation révèle quelque chose de vrai sur la façon dont les praticiens RH abordent les outils d’IA en ce moment. Le fossé que beaucoup d’entre eux traversent n’est pas entre savoir que quelque chose existe et l’utiliser. C’est entre croire qu’ils sont capables de faire ce genre de choses eux-mêmes.
Une démo montrant des praticiens construisant leur propre outil répond à une autre question qu’un produit fini—non pas « cet outil est-il bon ? », mais « quelqu’un comme moi aurait-il pu le créer ? »
L’idée a été bien accueillie. Elle répondait aux préoccupations liées aux tests, réduisait la complexité de partager quelque chose qui n’était pas prêt pour la production, et maintenait l’accent là où la cohorte l’avait toujours voulu : sur le processus et la réflexion, pas uniquement le résultat final.
Ce que l’expérience a enseigné : Guide pour les bâtisseurs RH
- Partez du problème, pas de la technologie. L’enthousiasme initial du groupe pour l’analyse de sentiments était sincère et les a détournés d’un problème plus abordable et plus valable. Le pivot vers la cartographie de compétences a fonctionné parce qu’il partait d’un cas d’usage réel déjà éprouvé sur le terrain.
- Le sur-mesure l’emporte sur le générique. Tous les participants ont rencontré les limites des plateformes RH d’entreprise. Les outils construits pour des contextes spécifiques—le recommandateur d’avantages sociaux de Turnmeyer, la carte thermique de Satterfield—ont dépassé les alternatives sur étagère. Construire son propre outil n’a jamais été aussi pertinent et les obstacles sont moindres.
- La vérification croisée est la clé. Les auto-évaluations ne valent que par la connaissance de soi, qui est notoirement faillible. La vraie valeur d’un outil réside dans sa capacité à sonder, challenger et recadrer en douceur—et pas simplement à enregistrer ce que les gens pensent d’eux-mêmes.
- Minimum Valuable, pas Minimum Viable. Si la première version n’apporte pas assez pour donner envie à un utilisateur de revenir, la feuille de route importe peu. Pensez à la première impression, pas à la cinquième.
- L’adhésion est structurelle, pas accessoire. Savoir si c’est l’IA qui rend la note finale ou si c’est l’utilisateur qui la confirme n’est pas un détail UX. Cela détermine si l’outil est une autorité ou un collaborateur, et cette distinction façonne toute la façon dont il est perçu et utilisé.
- Supprimez les fonctionnalités déjà développées. La logique des coûts irrécupérables conduit les équipes à rajouter des éléments dans lesquels elles ont investi, bien après que ceux-ci ont cessé d’être pertinents. Si vous ne pouvez expliquer à quoi sert une fonctionnalité, c’est votre réponse. La supprimer est une preuve de rigueur produit, pas un échec.
- Testez à l’encontre, et très tôt. Trouvez des personnes prêtes à vous dire que l’outil n’est pas bon. Donnez-lui la pire entrée raisonnable que vous puissiez imaginer et voyez ce qu’il en fait. Traitez les cas limites avant de polir les cas typiques. La crédibilité de l’outil dépend de la façon dont il gère les situations pour lesquelles il n’a pas été conçu.
- L’outil doit mériter le droit d’évaluer. Passer à la notation sans poser assez de questions, c’est de la présomption, pas de l’efficacité. Les questions de clarification rendent l’évaluation défendable, et c’est cette défendabilité qui fait que les retours s’ancrent.
- Soyez honnête sur les intentions de chacun. Les divergences d’intention dans un groupe ne sont pas un problème à gérer, mais des informations. Les mettre sur la table dès le début évite à tous de s’investir dans la poursuite d’un objectif que seuls quelques-uns partagent réellement.
- Les conversations les plus difficiles sont les plus importantes. La cohorte a élaboré un outil d’évaluation des compétences RH, et ce faisant, a eu l’une des discussions les plus honnêtes qu’ils aient jamais connues sur les limites de la fonction RH. Cette conversation—sur les cadres obsolètes, sur l’écart entre la connaissance théorique et le jugement situationnel—faisait partie du produit autant que l’outil lui-même.
Les sessions, initialement prévues sur quatre appels, se sont prolongées tout l’hiver puis jusqu’à la nouvelle année. Le prototype évoluait toujours. Les intentions de ceux qui l’avaient construit s’étaient précisées, mais pas de manière parfaitement tranchée.
Satterfield était encore en train de construire. Turnmeyer avait tiré parti de ce qu'elle avait appris et l'avait appliqué ailleurs. Gillies avait poussé le groupe à être plus discipliné quant à l'objectif réel de l'outil. J'écrivais l'histoire de tout cela.
Turnmeyer avait dit quelque chose au début du processus qui est resté vrai : elle construisait non pas parce qu'on le lui avait demandé, mais parce qu'elle avait besoin de comprendre.
Cette compréhension de ce que font réellement les outils d'IA, de ce qu'ils font mal, de ce qu'il faut pour les rendre utiles, n'était abordée dans aucune session de conférence ni démonstration de fournisseur. Elle venait des décisions prises par le groupe, des fonctionnalités abandonnées, des moments où l'outil évaluait quelqu'un de manière incorrecte et qu'ils devaient comprendre pourquoi.
Les choses les plus précieuses produites par la cohorte ne se trouvaient pas dans le prototype. Elles étaient dans le raisonnement qui l'avait guidé.