{kind=link}
Quando i Leader delle Risorse Umane Diventano Costruttori

Intuizione dall'Esperimento: I progetti collaborativi di intelligenza artificiale hanno fornito profonde intuizioni sulle capacità HR, andando oltre lo sviluppo stesso dello strumento.
Focalizzazione sul Problema: Passare dall'analisi del sentiment alla mappatura delle competenze ha evidenziato l'importanza di definire obiettivi chiari e raggiungibili.
Scetticismo verso l'AI: I professionisti HR affrontano sfide significative riguardo alla responsabilità e trasparenza nelle piattaforme AI esistenti.
Struttura dello Strumento: Lo strumento di valutazione AI ha enfatizzato la collaborazione, consentendo agli utenti di confermare o contestare i feedback generati dall'AI.
Test Avversariali: Lo sviluppo efficace di uno strumento richiede test rigorosi con input diversificati per gestire adeguatamente i casi limite.
Le riunioni erano programmate per durare un'ora. Quasi sempre andavano oltre il tempo previsto.
Non è insolito quando si riunisce un gruppo di professionisti HR per parlare di intelligenza artificiale. Ciò che invece era insolito era ciò che veniva richiesto loro di fare con quella conversazione. Non analizzarla, né pubblicare un articolo di opinione, ma costruire davvero qualcosa.
Nell'autunno del 2025, ho riunito quelli che chiamavo builder cohort: un piccolo gruppo di professionisti HR e delle operations aziendali che avevo identificato come già impegnati sul campo, già proiettati ai margini di ciò che la professione HR potrebbe fare con l'IA.
L'ipotesi era semplice. Le persone più vicine ai problemi sono quelle meglio posizionate per costruire le soluzioni. La domanda era se fossero in grado di farlo.
In totale avrei formato quattro gruppi e, nel frattempo, realizzato che fissare gli obiettivi per queste sessioni è più facile a dirsi che a farsi. Alla fine, la maggior parte dei gruppi si è sciolta, faticando a concretizzare la visione iniziale o a concentrarsi su uno scopo unico. Gli impegni lavorativi, le agende e le reali esigenze lavorative spesso portavano a conversazioni ricche di idee brillanti che però non venivano mai realizzate.
Ma un gruppo è riuscito davvero ad arrivare fino in fondo come meglio poteva. La realtà è che, più si scende nella tana del coniglio del costruire in proprio, più diventa difficile mantenere una visione condivisa e affrontare la sfida ingegneristica.
Questa storia è il resoconto di ciò che è nato da quelle sessioni e la propongo come caso di studio su come costruire le proprie soluzioni.
Il gruppo




Non si trattava di scettici sull’IA da convincere. Erano professionisti che avevano già puntato su questo momento. Ciò che la coorte offriva era uno spazio strutturato per smettere di consigliare e iniziare a creare.
La prima conversazione sincera
La prima sessione ha fatto emergere qualcosa che raramente si trova nei commenti pubblicati sull’HR: quanto questi professionisti siano realmente frustrati dagli strumenti che dovrebbero usare.
Turnmeyer ha dato il tono. Aveva cercato di ottenere documentazione tecnica su come funzionasse l’analisi del sentiment all’interno di BambooHR, Paycom e Gusto: non per screditare gli strumenti, ma perché il suo team legale aveva bisogno di capirne il funzionamento prima di approvarne l’uso.
Né il team commerciale né i rappresentanti legali hanno saputo rispondere alle sue domande. Le funzionalità di IA esistevano. La responsabilità su come funzionassero invece no.
Gillies si trovava ad affrontare una tensione analoga. Voci interne avevano sollevato preoccupazioni sull’impatto ambientale dell’IA, e alcuni colleghi volevano semplicemente vietare l’uso dell’IA ai dipendenti. Gillies si è opposta.
Proibire completamente l'IA porta a un uso nascosto e a un rischio maggiore. Accogliere l'IA con delle regole è un approccio migliore.
Melina Gillies · Chief of People, Flex Networks
Quella prima ora portò a una diagnosi sulla quale il gruppo poté concordare. Le funzionalità di IA integrate nelle piattaforme HR aziendali erano, come ha detto Gillies, "spesso basilari e con funzionalità limitate."
Gli strumenti che funzionano davvero tendono ad essere su misura—sviluppati per problemi specifici, contesti specifici, aziende specifiche. Turnmeyer voleva meno strumenti, non di più, un ritornello che sento spesso da leader delle persone e delle operations. Poteva immaginare un futuro in cui una IA capace, alimentata con i documenti giusti, rendesse superfluo un HRIS.
Hanno anche affrontato qualcosa che raramente viene messo in discussione in modo così diretto: l'etica del tracciamento comportamentale. L'idea di usare il tasso di rifiuto delle riunioni, i vuoti di login ai sistemi o orari di lavoro insoliti come indicatori di disimpegno è emersa fin dall'inizio.
Ma anche i limiti di questo approccio sono stati discussi. Satterfield ha citato un rischio che ogni strumento di engagement prima o poi affronta: la "fatica da inattività." Se raccogli dati ma non agisci in modo visibile, i dipendenti smettono di fidarsi del sistema. I dati diventano rumore e lo strumento diventa teatro dell'IA.
Non erano pronti a costruire uno strumento di analisi del sentiment. Era troppo ampio, carico di dilemmi etici e troppo facile da sbagliare in modo catastrofico. Così hanno cambiato rotta.
Trovare il problema giusto
La seconda sessione è iniziata con un’onesta ammissione: la direzione originale era troppo ambiziosa e troppo vaga.
"Non so se quello misura davvero l'engagement," ha detto Turnmeyer, "o se misura solo qualcosa che necessita semplicemente di una conversazione."
Questa distinzione è più importante di quanto sembri. Molte tecnologie HR commettono l’errore di trattare i dati come sostituti delle conversazioni. Il gruppo stava cercando di usare l'IA per far emergere i momenti in cui una conversazione è necessaria e poi renderla più efficace.
Satterfield ha introdotto l’idea che avrebbe guidato il resto del progetto. Durante un blocco delle assunzioni presso un precedente datore di lavoro, aveva creato un’autovalutazione delle competenze per il team di talent acquisition—un modo per mappare ciò che le persone potevano fare rispetto a ciò che volevano realmente fare, generando una mappa termica che rendeva le decisioni di riallocazione più umane e più strategiche.
Non era basato sull’IA. Era un modulo Microsoft Forms. Ma la logica sottostante era solida, il caso d’uso reale, e aveva visto funzionare il sistema.
"I grandi fornitori stanno cercando di fare questo, ma nessuno lo sta facendo davvero bene e molte aziende non hanno budget destinati per questa tecnologia oltre al loro HRIS principale," ha detto.
Il gruppo vide l’opportunità. E se costruissero una versione nativa IA? Una che fosse conversazionale invece che clinica, proiettata nel futuro invece che guidata solo dalla conformità, e con un prezzo accessibile ai singoli leader HR anziché blindato da contratti enterprise?
Il modo in cui l’HR parla a se stesso di HR è dinamicamente diverso. Questo può essere un vero valore e la maggior parte degli strumenti lo perde completamente.
Melina Gillies · Chief of People, Flex Networks
Fisher, ascoltando mentre il gruppo valutava le possibilità, ha fatto un’osservazione che ha cambiato la prospettiva sul potenziale del progetto. Aveva vissuto entrambi gli estremi dell’HR: quello orientato alla compliance, con i suoi framework e la sua natura transazionale, e il più raro professionista orientato alle persone, che parlava con lui "come una persona che si schierava dalla mia parte."
"Il linguaggio del secondo tipo," disse, "non sembrava mai venire da un framework scritto decenni fa. Semplicemente faceva stare bene."
Gillies coglie subito il punto. Il vero fattore distintivo per il loro strumento, argomentava, era il tono e la struttura. E se potesse replicare il modo in cui i professionisti HR parlano davvero tra loro a una conferenza, tra una sessione e l’altra, fuori dagli atti ufficiali? E se comprendesse l’essere "politicamente avveduto" non come una checkbox ma come una questione carica di sfumature, discussa e dibattuta tra professionisti esperti?
Quella era la direzione: uno strumento di valutazione pre-assunzione progettato per leader HR e talent acquisition che hanno bisogno di nuovi modi per valutare i candidati recruiter prima di assumerli. Non un test della personalità o un filtro CV, ma un diagnostico strutturato e conversazionale in grado di dire a chi assume se la persona davanti a sé sa davvero fare il mestiere. Qualcosa che assomiglia meno a una valutazione delle prestazioni e più a una conversazione con qualcuno che capisce il recruiting dall’interno.

Il momento della lampadina
Alla terza sessione, il gruppo era immerso nell’architettura dello strumento: quali competenze valutare, come strutturarle sui diversi livelli, come considerare il divario tra ciò che le persone dicono di saper fare e ciò che realmente fanno.
La critica ai framework esistenti arrivava da Gillies, che descriveva il modello di competenze SHRM come "molto tradizionale e per certi versi rivolto al passato." La professione era ancora, per usare le sue parole, in una "sbronza postindustriale"—basata sulla compliance, gerarchica, pensata per un mondo che già stava svanendo.
Il loro strumento doveva orientarsi verso qualcos'altro, non a ciò che i leader delle risorse umane dovevano sapere, ma a ciò che dovevano essere in grado di fare.
Saresti disposto a parlare con l’amministratore delegato delle sue prestazioni? Se non lo sei, non sei un esperto nelle conversazioni difficili.
Erin Turnmeyer · VP of People Operations
Turnmeyer aveva un esempio illuminante. Aveva recentemente sostenuto l’esame SPHR. Le cose che le veniva richiesto di sapere—statuti, definizioni procedurali, regole di classificazione—erano cose che qualsiasi professionista HR competente semplicemente consultava.
Le competenze vere non erano il materiale della certificazione. Erano domande come: riesci a sederti di fronte a un amministratore delegato e dirgli qualcosa che non vuole sentire? Sai sostenere un dipendente quando il business case è ambiguo? Memorizzare i codici del lavoro non risponde a queste domande.
Fisher andò oltre. Aveva trascorso anni nella gestione del cambiamento, e aveva scoperto che la variabile più predittiva della capacità di un’organizzazione di navigare la trasformazione non era una competenza specifica. Era il rapporto di una persona con l’ambiguità.
Capire quanto qualcuno si senta a suo agio nell’essere a disagio—o con il ritmo del cambiamento in generale—è un grande indicatore della sua capacità di funzionare in questo nuovo mondo.
Tim Fisher · Head of AI , Black and White Zebra
Arrivò poi quello che il gruppo avrebbe poi chiamato l’ingrediente segreto.
Gillies pose una domanda. E se lo strumento avesse una funzione di verifica incrociata? Se qualcuno si autovalutasse esperto nella gestione dei conflitti, ma poi, in una risposta libera a una domanda successiva, descrivesse situazioni che di esperto sembrano avere ben poco, l’AI potrebbe segnalarlo? Potrebbe dire, con garbo, che forse c’è un divario?
"Questo è il momento della lampadina," disse Turnmeyer.
Satterfield osservò che chiunque abbia lavorato con le analisi dell’inventario delle competenze ha già visto versioni dello stesso problema. Le persone spesso si attribuiscono valutazioni molto diverse rispetto a quanto suggerirebbero la loro esperienza o il loro comportamento reale.
Il valore dello strumento non deriverebbe dal registrare ciò che le persone pensano di sé. Verrebbe dalla calibrazione—quel leggero attrito, informato dai dati, tra auto-percezione e competenza dimostrata.
La valutazione non sarebbe solo uno specchio. Sarebbe più uno “specchio, specchio delle mie brame” rispetto a quanto la maggioranza delle persone si aspetta dagli assessment lavorativi.
Le realtà della costruzione
Niente di tutto ciò era facile. E il gruppo lo sapeva già dall'inizio.
La sfida più persistente non era tecnica. Era la definizione dell'ambito. Ogni sessione generava dieci nuove direzioni, tutte davvero valide, ognuna capace di divorare l'intero progetto. Turnmeyer l’ha identificata da subito e l’ha ricordata spesso.
"Assicurati che faccia bene la prima cosa, così non allarghi l’ambito al punto da non riuscire più a crearla," disse.
Satterfield introdusse un principio guida per il gruppo: la differenza tra un Minimum Viable Product e un Minimum Valuable Product. Un prodotto funzionante è valido. Un prodotto di valore fa sì che le persone vogliano tornarci.
In un mercato saturo di strumenti di valutazione, un’interfaccia che non fornisce qualcosa di significativo alla prima interazione non avrà una seconda occasione per migliorarsi. La soglia non è la funzionalità. È il valore.
Se il prodotto non fornisce abbastanza valore al primo accesso, è probabile che gli utenti non tornino più a vedere se è cambiato in meglio.
Kelly Satterfield · HR Leader and Consultant
Esistono poi vincoli pratici che chiunque abbia provato a costruire qualcosa fuori da un team di sviluppo conosce bene: il deployment, i sistemi di pagamento, l’integrazione con sistemi già esistenti, finestre di contesto che si chiudono a metà sessione cancellando ore di lavoro produttivo.
La prima versione rispecchiava il flusso principale dello strumento. Un candidato per un ruolo da recruiter carica il curriculum, lo strumento deduce un profilo di competenze preliminare, e poi lo guida attraverso una serie di domande conversazionali pensate per calibrare e aggiungere contesto e profondità a quella prima lettura.
Alla fine, un responsabile delle selezioni ottiene una fotografia di dove effettivamente il candidato si colloca rispetto a un quadro di competenze ben definito.
Fisher ha impiegato Lovable come ambiente principale di sviluppo—un generatore di AI no-code che crea strumenti pubblici attraverso la conversazione, senza vincolare gli utenti a uno specifico LLM—così che l’architettura tecnica potesse seguire il pensiero del gruppo senza diventare un collo di bottiglia.
Dal progetto alla realizzazione
Alla quarta sessione, il gruppo non stava più progettando uno strumento astratto. Ne stavano costruendo uno, e scoprivano come ogni costruttore che la distanza tra l’idea e la sua realizzazione è proprio il luogo dove accade il vero apprendimento.
Fisher aveva assemblato un GPT personalizzato di base prima della chiamata, caricato con istruzioni, un framework preliminare di competenze e le prime logiche conversazionali che avevano mappato nelle sessioni precedenti. Il piano era che tutti vi accedessero, lo interpellassero in modo collaborativo e iniziassero a calibrare in tempo reale la sua voce e il suo comportamento. Il piano si è subito scontrato con la realtà.
Il link condiviso funzionava solo per me. Permessi dell'area di lavoro, particolarità della piattaforma e il modo in cui ChatGPT gestisce l'accesso esterno hanno consumato il primo quarto della sessione.
È stata una piccola frustrazione, proprio di quel tipo che non finirebbe mai in un comunicato di prodotto, ed è stata istruttiva. Gli strumenti che i professionisti usano realmente per costruire cose non si comportano come nelle demo.

Questo screenshot mostra come sarebbe diventata la schermata di benvenuto dello strumento costruito dal gruppo, chiamato Talent Scout.
Una volta che tutti stavano guardando la stessa schermata, è successo qualcosa di più interessante. Mentre il gruppo stava ancora discutendo su quale formato dovessero avere le definizioni delle competenze, Gillies ha aperto Claude in una finestra separata e ha convertito la tabella dei punteggi in JSON strutturato—dal vivo, durante la chiamata.
"Uso Claude perché è migliore di ChatGPT per questo", ha detto, senza cerimonie. Ha caricato il file formattato nella chat di gruppo pochi minuti dopo. Nessuno si è fermato a commentarlo. Sono semplicemente andati avanti.
Quel tipo di problem solving in movimento—trasformare un collo di bottiglia in un problema risolto senza farlo diventare il centro della riunione—è ciò che distingue i professionisti che hanno veramente interiorizzato questi strumenti da chi sta ancora imparando a gestirli.
Chi ha l'ultima parola
Satterfield ha sollevato una domanda che avrebbe avuto implicazioni significative sia per l'architettura dello strumento sia per la sua futura accoglienza: è l'AI a fornire la valutazione finale, o è l'utente a confermarla?
La distinzione non è estetica. Se lo strumento fornisce un verdetto come "In base alle tue risposte, sei al Livello 2 nella focalizzazione sul candidato", allora pone l'AI come autorità. Se invece presenta una lettura provvisoria e invita l'utente a controbattere, la dinamica cambia completamente. La valutazione diventa collaborativa piuttosto che valutativa. L'utente è parte attiva del processo, non un soggetto passivo.
"Accetti questo feedback?" ha detto Turnmeyer, appena l'idea è stata proposta. "Mi piace molto, in effetti."
Gillies ha sviluppato la logica. Se l'utente non accetta la valutazione, lo strumento chiede cosa non convince e poi utilizza la risposta per ricalibrare o riconfermare dolcemente la propria lettura, illustrando le prove.
Quello scambio conversazionale è ciò che crea la sicurezza psicologica di cui lo strumento ha bisogno per essere davvero utile. Le persone non cambiano sulla base di feedback che non considerano affidabile. L'accordo emotivo non è una caratteristica "soft", è il meccanismo stesso.
La prima vera prova
Hanno deciso di testare il prototipo in diretta. Turnmeyer si è offerta di fornire una risposta volutamente superficiale a una delle domande della valutazione—del tipo che potrebbe dare un candidato disinteressato o un dipendente distratto.
Ha descritto una discussione con il proprio responsabile su una discrepanza salariale, la perdita del candidato e il fatto di non avere idea di quale fosse stato l'esito. Era l'equivalente HR del rispondere "Mi piacciono davvero le persone" quando ti chiedono perché vuoi lavorare nelle risorse umane.
Lo strumento l'ha valutata immediatamente. Ha assegnato un livello. È stato incoraggiante. Era anche sbagliato, non nei fatti, ma prematuro. Aveva fatto delle ipotesi su ciò che la risposta implicava invece di chiedere il contesto aggiuntivo di cui avrebbe avuto bisogno per valutare accuratamente.
Se stai per dare a qualcuno qualcosa di diverso da "soddisfa le aspettative", devi fornire esempi dettagliati. L'AI dovrebbe attenersi allo stesso standard.
Erin Turnmeyer · VP People Operations
Turnmeyer ha tratto parallelismo diretto dalla sua pratica nelle revisioni delle performance. Aveva da tempo richiesto che i manager fornissero prove specifiche prima di valutare qualcuno sopra o sotto il "soddisfa le aspettative."
La stessa disciplina dovrebbe valere per lo strumento. Prima di assegnare un livello, bisogna guadagnarsi il diritto di farlo ponendo domande che rendano la valutazione difendibile. Era, ancora, l'esperienza HR nella stanza a migliorare l'AI—non il contrario.
Satterfield ha aggiunto una complicazione che lo strumento aveva trascurato. La risposta superficiale poteva riflettere una politica aziendale più che un'abilità.
Se il manager avesse davvero stabilito un tetto salariale fisso, insistere di più non avrebbe cambiato il risultato. Lo strumento aveva valutato la persona quando avrebbe dovuto chiedere della situazione. Le domande di chiarimento non erano un dettaglio accessorio. Erano ciò che avrebbe distinto una valutazione utile da una presuntuosa.
Turnmeyer ha preso come compito per casa la scrittura delle istruzioni: come fare in modo che uno strumento ponga domande di chiarimento nei momenti giusti senza trasformare ogni interazione in un interrogatorio?
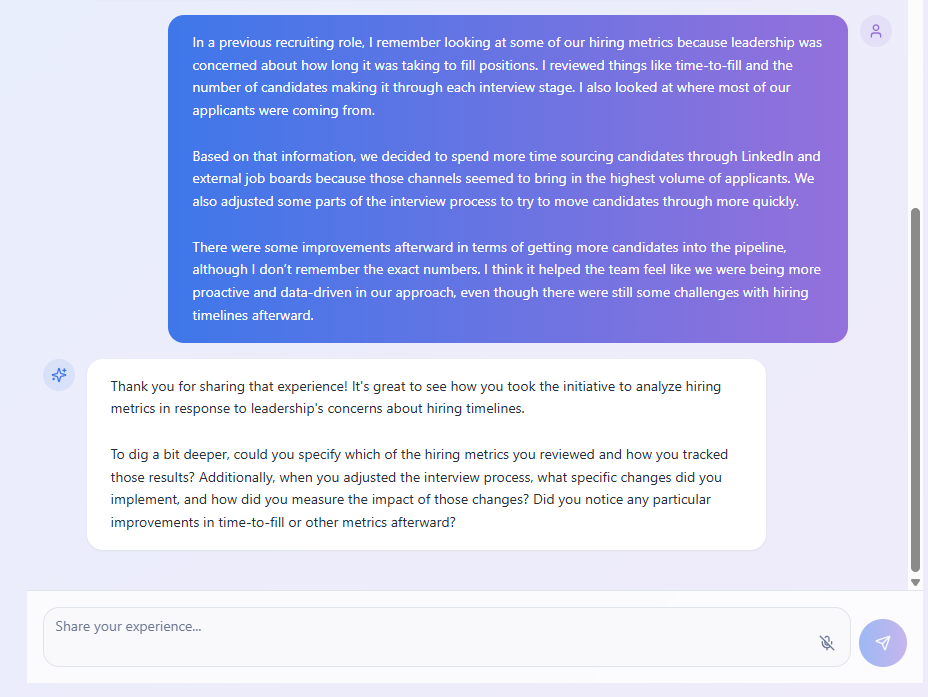
Questo screenshot mostra un esempio di ciò che il prodotto finale dovrebbe fare: porre domande chiarificatrici e spingere il candidato ad approfondire maggiormente.
È un problema più difficile di quanto sembri, e lei era ben consapevole che lo standard richiesto era insolitamente elevato.
"Deve essere migliore di un essere umano," ha detto. "Questo è lo standard."
Il test come disciplina
La sessione ha anche prodotto una delle intuizioni metodologiche più utili dell'intero gruppo. Quando Satterfield ha chiesto come il gruppo solitamente testasse strumenti di questo tipo, sia Turnmeyer che Gillies hanno risposto in modo da rivelare qualcosa di importante su cosa significhi, nella pratica, testare con rigore.
Per il suo strumento di raccomandazione sui benefit, che doveva indicare con precisione se determinati farmaci fossero coperti dal piano sanitario aziendale, Turnmeyer ha testato specificamente i casi limite. Non i farmaci ovvi, quelli popolari che il modello avrebbe incontrato ripetutamente durante l'addestramento. Ha testato quelli più sconosciuti, nelle categorie più soggette a produrre una allucinazione sicura di sé.
"Sono andata a testare proprio i farmaci non popolari," ha detto, "perché Claude mi ha mostrato cosa stava facendo mentre lo costruiva."
Quel livello di intenzionalità avversariale nel testing è raro tra chi costruisce strumenti venendo da un contesto non ingegneristico. Ed è proprio questo che distingue gli strumenti che guadagnano fiducia da quelli che vengono abbandonati silenziosamente dopo un errore imbarazzante.
Tagliare ciò che hai già costruito
Una sessione di confronto, poco prima delle vacanze, è iniziata con una domanda più difficile di quanto sembri: a cosa serve davvero la funzione di caricamento del curriculum?
Gillies ha sollevato il tema. La valutazione chiedeva agli utenti di riflettere attentamente sulle proprie competenze. Il curriculum aggiungeva informazioni che l’utente non poteva fornire in modo più diretto rispondendo semplicemente alle domande? Nessuno nel gruppo ne era sicuro. L’intento originale era far risparmiare tempo, come farebbe un parser di curriculum, ma non eravamo più convinti che funzionasse davvero.
Hanno deciso di tagliarlo.
Questa scelta è più rara di quanto sembri nello sviluppo di prodotto. Il gruppo aveva dedicato vero tempo alla funzione di caricamento—costruendola, testandola, guardando il curriculum di Satterfield venire analizzato e valutato male. Tagliarla ha significato ignorare la logica del costo irrecuperabile che spesso spinge i team ad aggiungere su cose su cui hanno già investito.
Partire dalla fine e definire chiaramente cosa significa un buon risultato. Se non sai spiegare a cosa serve una funzione, non puoi difenderla.
Turnmeyer ha fatto un’osservazione collegata sulla metodologia. A posteriori, pensava che avrebbero potuto andare più veloci definendo completamente il comportamento dello strumento prima di scrivere anche solo una prompt. Stavano seguendo una specie di modello agile—costruisci, testa, aggiusta—quando la complessità di ciò che stavano creando forse richiedeva un approccio più da waterfall: prima definisci bene le specifiche, poi costruisci.
Aveva un documento di design di 130 pagine per un altro strumento che aveva costruito, che le aveva insegnato questa lezione. Un documento delle specifiche completo non ti dice solo cosa devi costruire. Ti dice anche cosa NON devi costruire, il che si rivela ugualmente utile.
Gillies ha affinato il problema fondamentale del prodotto. Qualunque cosa mostrasse lo strumento a schermo doveva andare oltre. Una valutazione che presenta dati non è la stessa cosa di uno strumento che ti dice cosa farci. Quel divario tra output e azione è il punto in cui gli strumenti diagnostici smettono silenziosamente di essere utili, e la maggior parte non riesce mai a colmarlo.
Costruire da soli
A gennaio, Satterfield stava facendo la maggior parte del lavoro da sola, mentre il resto del gruppo trovava il lavoro dalle 9 alle 17 troppo impegnativo per lasciare spazio al progetto. In fondo, nessuno era pagato per questo.
Aveva eliminato il caricamento del curriculum, come il gruppo aveva deciso. Aveva aggiunto l’input vocale: gli utenti ora potevano rispondere alle domande dell’assessment parlando invece che scrivendo, il che apriva a uno stile di risposta più conversazionale, meno facilmente manipolabile rispetto a un campo di testo.
Utilizzava ChatGPT per generare risposte di test sintetiche ("Sono un junior recruiter forte in questo e debole in quello, dammi le risposte"), per poi passare su Lovable e inserire quelle risposte, osservando come lo strumento le valutava.
La dashboard del leader era l'altra metà della logica dello strumento: la vista che un direttore TA o un CHRO avrebbe utilizzato per vedere come un candidato era stato valutato, dove si trovavano le lacune e come le loro capacità potessero completare i punti di forza e le necessità di un team esistente.
Questo rendeva la struttura organizzativa un vero problema perché lo strumento doveva sapere chi stava valutando chi e chi aveva l’autorizzazione per vedere i risultati.
Satterfield aveva cercato di gestire la situazione chiedendo agli utenti di inserire nome, titolo di lavoro e nome del manager (in assenza di un’integrazione dati). Ma quella logica si rompeva in uno scenario comune: un direttore della talent acquisition che voleva inviare la valutazione a un'organizzazione di reclutamento più ampia, comprendente sia rapporti diretti che indiretti. La logica di mappatura dell’organigramma non era abbastanza raffinata per tenere conto di quella struttura.
In teoria, queste informazioni avrebbero dovuto fornire allo strumento un contesto maggiore sul ruolo della persona valutata, ma raccogliere più dati ha complicato le cose.
Turnmeyer aveva già risolto una versione di questo problema in un contesto diverso. Lo strumento di gestione delle performance che aveva creato per la sua azienda si basava su Google Sheets, Slack e Claude. Google Sheets archiviava i dati. Slack era l’interfaccia con cui gli impiegati interagivano. Claude gestiva l’analisi e la generazione dei feedback.
L’architettura era più semplice di quanto sembrasse: un foglio di calcolo con nome, email, livello lavorativo e titolo di lavoro. Una scheda separata mette in relazione il livello lavorativo con le competenze.
"La sicurezza nella mia azienda voleva revisionare il mio strumento,” ha detto al gruppo. “Ho spiegato che era memorizzato in Google Docs. Loro hanno risposto: ‘Ah, è così semplice.’”
Semplice, ma Turnmeyer l’ha imparato solo costruendo. Quello che non sapeva tre settimane prima era che esistesse il logging – una funzione che salva il progresso di un utente così che lo strumento non si resetti quando qualcuno si allontana e poi ritorna.
"Stavo bestemmiando contro Claude,” ha detto, “finché non mi ha detto che il logging esisteva."
È proprio costruendo che si impara davvero. Non impari la cosa che avevi previsto, ma quella che non sapevi nemmeno di dover sapere.
La Domanda Sottostante
Da qualche parte, durante la sessione di gennaio, la conversazione arrivò alla domanda attorno alla quale si girava da mesi.
Il gruppo continuava a discutere di architettura, permessi, archiviazione, dashboard—problemi reali, tutti. Ma sotto tutto questo c’era un problema più fondamentale. Cosa stavano davvero cercando di costruire e per chi?
Lo strumento, come originariamente concepito, era un diagnostico di selezione: qualcosa che un leader TA poteva inviare a un candidato o a un dipendente interno per valutare se le loro reali capacità corrispondessero a quanto dichiarato nel CV, e mettere in luce questo quadro prima di prendere una decisione di selezione.
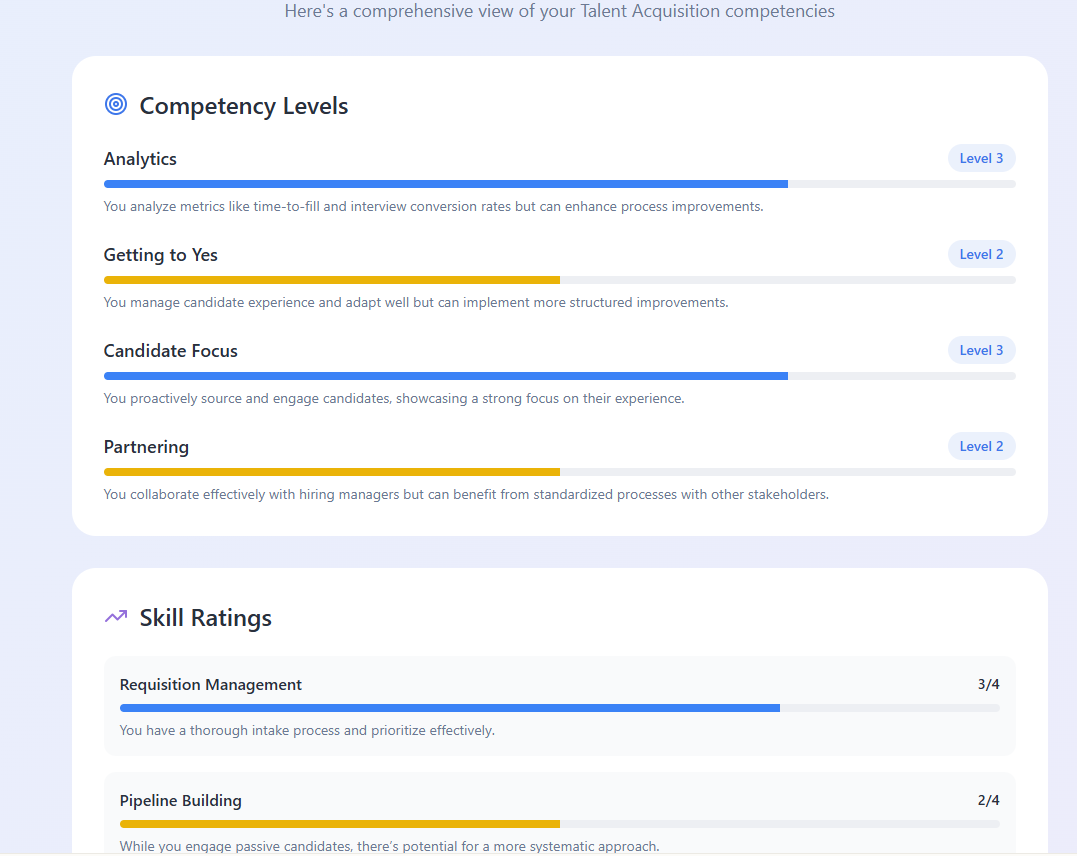
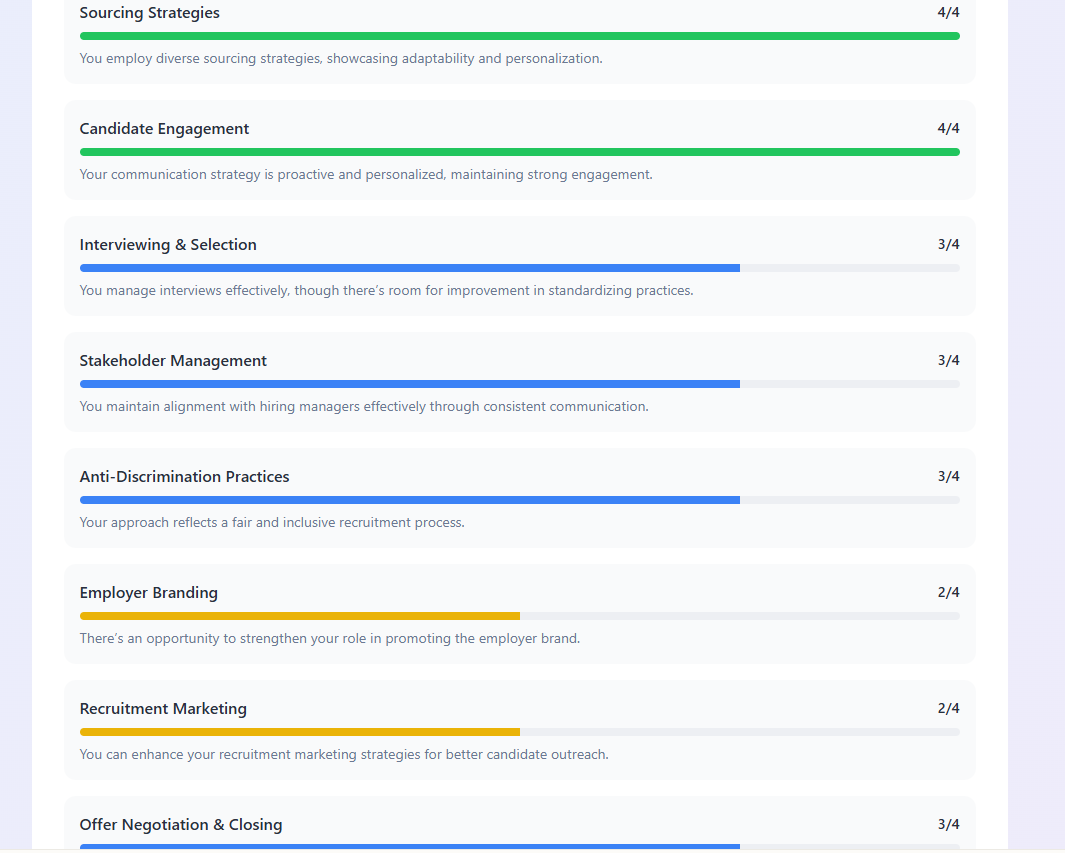

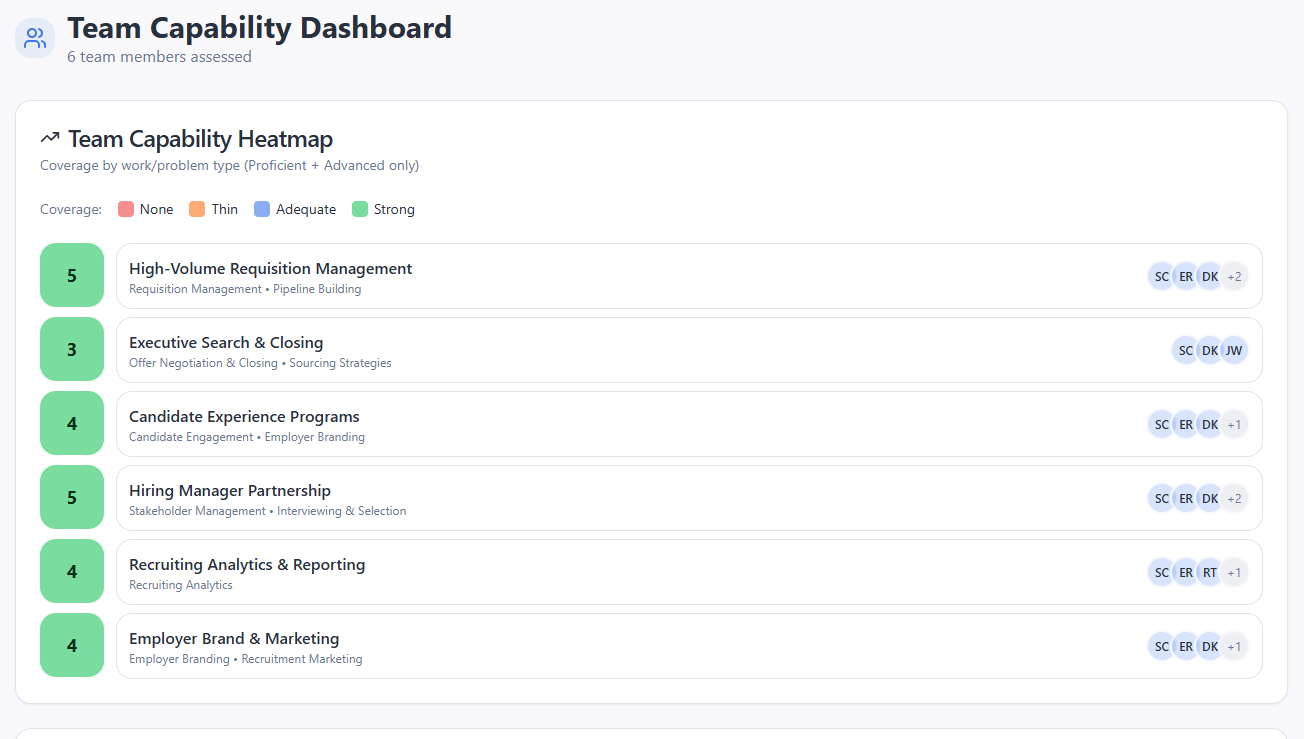
Quella che vedi qui è una selezione di screenshot del tipo di report che lo strumento produceva per l’intervistato. Per il valutatore, una dashboard sui punti di forza attuali del team lo aiuta a focalizzarsi su dove valutare il candidato per capire se può colmare le debolezze del team TA.
Quella base non era mai cambiata. Ma ogni decisione pratica che avevano preso—aggiungere una dashboard leader, pensare a modelli di abbonamento, studiare un flusso di accesso—li stava portando verso qualcosa di più complesso.
Dashboard in tempo reale significavano accesso continuativo, che si traduceva in costi di abbonamento, il che li portava sempre più vicino a quel tipo di strumentazione aziendale che molte organizzazioni faticano a permettersi o rendere effettivamente operativa.
"Non vogliamo diventare un fornitore HCM," ha detto Satterfield.
Turnmeyer è stata onesta su dove si trovava.
"Il mio intento era solo imparare qualcosa di nuovo."
Non era un ritiro dal progetto. Era una descrizione accurata di ciò che l’esperimento aveva già prodotto per lei. Aveva imparato cose nuove ed era già al lavoro su un nuovo strumento di gestione delle performance applicando le lezioni imparate dal gruppo.
Non aveva bisogno di trasformare lo strumento del gruppo in un prodotto per averne ricavato un vero valore.
A questo punto, il mio interesse era principalmente editoriale. Volevo una storia da raccontare e qualcosa che la gente potesse vedere, non un prodotto in abbonamento, ma una dimostrazione che i professionisti HR potessero considerare e magari replicare.
Scrivere questo articolo ne faceva parte. Potevo creare una guida scaricabile? Magari, col tempo, un evento dal vivo in cui il gruppo avrebbe potuto discutere ciò che era stato fatto, permettere al pubblico di interagire con lo strumento e registrare la conversazione come podcast? Avevo molte idee, ma il tempo per realizzarle, man mano che gli obiettivi per il nuovo anno si accumulavano davanti a tutti noi, si stava assottigliando.
L’interesse di Satterfield era il più orientato al business, e lei lo dichiarava apertamente. Era interessata a farne un prodotto, prima o poi. Non lo avrebbe fatto da sola. Ma era disposta a continuare a costruire qualcosa che un giorno potesse essere venduto.
Quella triplice divergenza di intenti—apprendimento, narrazione, prodotto—probabilmente è insita in qualsiasi gruppo di questo tipo. La conversazione onesta a riguardo, a gennaio, è stata più utile che fingere che tutti avessero sempre voluto la stessa cosa.
La demo come risposta
La questione su come permettere alle persone di provare lo strumento era rimasta irrisolta da quando il caricamento del curriculum era andato online. Testare con utenti reali è prezioso, ma crea problemi propri. Lo strumento deve funzionare in modo affidabile, gli utenti devono avere abbastanza contesto per capire cosa stanno facendo e una cattiva prima esperienza è difficile da recuperare.
Turnmeyer ha proposto la soluzione più semplice che il gruppo avesse mai considerato.
Stava guardando registrazioni di demo—brevi walkthrough, di un minuto o due, che mostrano come funziona uno strumento senza richiedere all’osservatore di usarlo effettivamente. Ha suggerito che potrebbe essere sufficiente. Le persone potevano vedere lo strumento in azione, capire cosa faceva e perché, e andarsene sentendo che fosse possibile farlo pure loro.
Non avrebbero dovuto navigare un login, fornire un organigramma o bloccarsi quando una domanda di valutazione non corrispondeva alla loro situazione.
Il feedback che ricevo da molti dei blog che scrivo è che le persone non vogliono davvero copiare e incollare esattamente la stessa cosa. Vogliono solo sapere di essere in grado di farlo.
Erin Turnmeyer · VP of People Operations
Quella osservazione evidenzia qualcosa di reale su come i professionisti HR si stanno relazionando agli strumenti di intelligenza artificiale in questo momento. Il divario che molti di loro stanno affrontando non è tra sapere che qualcosa esiste e usarlo. È tra credere di essere capaci di fare qualcosa del genere.
Una demo che mostra i professionisti mentre costruiscono il proprio strumento risponde a una domanda diversa da quella di un prodotto finito—non “questo strumento è buono?” ma “qualcuno come me potrebbe averlo realizzato?”
L’idea è stata ben accolta. Ha risolto le preoccupazioni sui test, ridotto la complessità nel condividere qualcosa che non era ancora pronto per essere rilasciato in produzione e ha mantenuto l’accento dove il gruppo aveva sempre voluto: sul processo e sul ragionamento, non solo sul risultato finale.
Cosa ha insegnato l’esperimento: una guida per costruttori HR
- Parti dal problema, non dalla tecnologia. L’entusiasmo iniziale del gruppo per l’analisi del sentiment era genuino e li ha allontanati da un problema più affrontabile e più valorevole. Il cambio verso la mappatura delle competenze ha funzionato perché partiva da un caso d’uso reale, già testato sul campo.
- Il su misura batte il generico. Ogni partecipante aveva sperimentato i limiti delle piattaforme HR aziendali. Gli strumenti costruiti per contesti specifici—il consigliere di benefit di Turnmeyer, la heat map di Satterfield—hanno superato le alternative preconfezionate. L’argomento in favore della costruzione di strumenti personalizzati è più forte che mai, e le barriere sono inferiori.
- Il controllo incrociato è tutto. Le autovalutazioni valgono solo quanto l’autoconoscenza delle persone, che è notoriamente inaffidabile. Il vero valore di uno strumento sta nella sua capacità di sondare, mettere in discussione, e correggere delicatamente—non solo nel registrare ciò che le persone credono di sé stesse.
- Minimo prezioso, non minimo vitale. Se la prima versione non offre qualcosa che faccia venir voglia all’utente di tornare, la roadmap non conta. Progetta per la prima impressione, non per la quinta.
- L’«engagement» è strutturale, non accessorio. La questione se sia l’IA a fornire la valutazione finale o sia l’utente a confermarla non è un dettaglio di UX. Determina se lo strumento è un’autorità o un collaboratore, e questa distinzione plasma tutto su come viene percepito e utilizzato.
- Taglia le funzioni che hai già costruito. La logica del “sunk cost” spinge i team ad aggiungere a ciò che hanno già sviluppato anche quando queste cose non servono più. Se non sai spiegare a cosa serve una funzione, hai già la risposta. Scegliere di toglierla è disciplina di prodotto, non fallimento.
- Testa in modo avversariale, e presto. Trova persone che ti dicano che lo strumento non va bene. Dagli l’input peggiore ragionevole che riesci a immaginare e guarda cosa fa. Gestisci i casi limite prima di rifinire quelli tipici. La credibilità dello strumento dipende da come gestisce i momenti per cui non era stato progettato.
- Lo strumento deve guadagnarsi il diritto di valutare. Arrivare subito a un rating senza fare abbastanza domande è presunzione, non efficienza. Le domande di chiarimento sono ciò che rende la valutazione difendibile, e la difendibilità rende il feedback duraturo.
- Sii onesto su cosa cerca ciascuno. Intenzioni divergenti all’interno di un gruppo non sono un problema da gestire—sono informazione. Metterle sul tavolo subito permette a tutti di evitare di lavorare per un obiettivo che solo alcuni realmente condividono.
- Le conversazioni più difficili sono le più importanti. Il gruppo ha costruito uno strumento per valutare le competenze HR e, nel farlo, ha avviato una delle conversazioni più oneste sulle limitazioni dell’HR che qualcuno di loro ricordasse. Quella discussione—sui framework antiquati, sulla distanza tra la teoria da esame e il giudizio situazionale—era il prodotto tanto quanto lo strumento stesso.
Le sessioni iniziate come un impegno di quattro incontri si sono protratte nell’inverno e poi nel nuovo anno. Il prototipo era ancora in evoluzione. Le intenzioni di chi lo aveva creato si erano chiarite in modi che non si risolvevano in modo lineare.
Satterfield stava ancora costruendo. Turnmeyer aveva preso ciò che aveva imparato e lo aveva applicato altrove. Gillies aveva spinto il gruppo a essere più disciplinato su cosa dovesse effettivamente fare lo strumento. Io stavo scrivendo la storia di tutto questo.
Turnmeyer aveva detto qualcosa all'inizio del processo che era rimasto vero: stava costruendo non perché qualcuno glielo avesse chiesto, ma perché doveva capire.
Quella comprensione di ciò che gli strumenti di intelligenza artificiale fanno realmente, di cosa sbagliano, di cosa serve per renderli utili, non era disponibile in nessuna sessione di conferenza o presentazione di fornitori. Veniva dalle decisioni prese dal gruppo, dalle funzionalità eliminate, dai momenti in cui lo strumento valutava qualcuno in modo errato e loro dovevano capire il perché.
Le cose più utili prodotte dal gruppo non erano nel prototipo. Stavano nel ragionamento che c’era dietro.