{kind=link}
When HR Leaders Become Builders

Experiment Insight: Collaborative AI projects provided profound insights into HR capabilities beyond just tool development.
Problem Focus: Switching from sentiment analysis to skills mapping highlighted the importance of defining clear, achievable goals.
AI Skepticism: HR professionals face significant challenges with accountability and transparency in existing AI platforms.
Tool Structure: The AI assessment tool emphasized collaboration, allowing users to confirm or challenge AI-generated feedback.
Adversarial Testing: Successful tool development requires rigorous testing with diverse inputs to address edge cases effectively.
The meetings were scheduled for an hour. They almost always ran long.
That's not unusual when you get a group of HR professionals together to talk about AI. What was unusual was what they were being asked to do with that conversation. Not analyze it, not publish a think piece about it, but actually build something.
In the fall of 2025, I assembled what I was calling builder cohorts: a small group of HR and people operations professionals I'd identified as already doing the work, already thinking at the edges of what the HR profession could do with AI.
The hypothesis was simple. The people closest to the problems are the ones best positioned to build the solutions. The question was whether they could.
In all I would build four cohorts, and along the way realize that defining goals for these sessions is easier said than done. In the end, most of the cohorts petered out, struggling to deliver on the initial vision or settle on a single aim. Calendars, workloads, the demands of our actual jobs, often led to conversations which yielded great ideas while never bringing them to fruition.
But one cohort came together and did in fact go the distance as best they could. The fact is, the deeper you go down the build it yourself rabbit hole, the harder and harder it gets to honor a shared vision and meet the engineering challenge.
This story is an account of what came from those sessions and I offer to you as a case study in building your own solutions.
The Cohort




These were not AI skeptics who needed convincing. They were practitioners who had already bet on this moment. What the cohort offered them was a structured space to stop advising and start making.
The First Honest Conversation
The first session surfaced something that rarely makes it into published HR commentary: how frustrated these professionals actually are with the tools they're supposed to use.
Turnmeyer set the tone. She'd tried to get technical documentation about how sentiment analysis worked inside BambooHR, Paycom, and Gusto—not to dismiss the tools, but because her legal team needed to understand them before approving their use.
Neither the sales teams nor the legal representatives could answer her questions. The AI features existed. The accountability for how they worked did not.
Gillies was navigating a parallel tension. Internal voices had raised concerns about AI’s environmental impact, and some colleagues wanted to simply ban employee AI usage. Gillies pushed back.
Outright outlawing AI leads to covert usage and increased risk. Leaning into AI with guardrails is a better approach.
Melina Gillies · Chief of People, Flex Networks
What emerged from that first hour was a diagnosis the group could agree on. The built-in AI features of enterprise HR platforms were, as Gillies put it, "often basic and lack functionality."
The tools that actually work tend to be bespoke—built for specific problems, specific contexts, specific companies. Turnmeyer wanted fewer tools, not more, a refrain I often hear from people and operations leaders. She could imagine a future where a capable AI, fed the right documents, made an HRIS unnecessary.
They also confronted something that rarely gets addressed this directly: the ethics of behavioral tracking. The idea of using meeting-decline rates, system login gaps, or unusual work hours as proxies for disengagement came up early.
So did the limits of that approach. Satterfield named a risk that every engagement tool eventually faces, inaction fatigue. If you collect data and don't act on it visibly, employees stop trusting the system. The data becomes noise and the tool becomes AI theater.
They weren't ready to build a sentiment analysis tool. It was too broad, too loaded with ethical conundrums, and too easy to get catastrophically wrong. So they pivoted.
Finding the Right Problem
The second session began with an honest admission that the original direction was too ambitious and too ambiguous.
"I don't know if that's measuring engagement," Turnmeyer said, "or if it's just measuring something that requires a conversation."
That distinction matters more than it might sound. A lot of HR technology makes the mistake of treating data as a substitute for conversation. The cohort was trying to use AI to surface the moments when a conversation needs to happen, and then make that conversation better.
Satterfield introduced the idea that would anchor the rest of the project. During a hiring freeze at a previous employer, she'd built a skills self-assessment for her talent acquisition team—a way to map what people could do against what they actually wanted to do, generating a heat map that made redeployment decisions more humane and more strategic.
It wasn't AI-powered. It was a Microsoft Form. But the underlying logic was sound, the use case was real, and she'd watched it work.
"Big vendors are trying to do this, but nobody's really doing it well yet, and many companies don’t have budget allocated for this type of technology in addition to their core HRIS," she said.
The group saw the opening. What if they built an AI-native version? One that was conversational instead of clinical, forward-looking instead of compliance-driven, and priced for individual HR leaders rather than locked behind enterprise contracts?
The way HR talks to HR about HR is dynamically different. That can be a real value and most tools miss it entirely.
Melina Gillies · Chief of People, Flex Networks
Fisher, listening as the group worked through the possibilities, offered an observation that reframed the project's potential. He'd experienced both ends of the HR spectrum: the compliance-first, framework-first, transactional kind and the rarer people-first practitioner who talked to him "like a person who felt like they were on my side."
"The language of the second kind," he said, "never felt like it came out of a framework written decades ago. It just felt good."
Gillies seized on that. The differentiator for their tool, she argued, was tone and structure. What if it could replicate the way HR professionals actually talk to each other at a conference, between sessions, off the record? What if it understood "politically savvy" not as a checkbox but as a loaded, contested, situationally complex thing that experienced practitioners argue about amongst themselves?
That was the direction: a pre-hire assessment tool designed for HR and talent acquisition leaders who need a better way to evaluate recruiter candidates before bringing them on. Not a personality quiz or resume screen but a structured, conversational diagnostic that could tell a hiring manager whether the person sitting across from them actually knew how to do the job. One that felt less like a performance review and more like a conversation with someone who understood recruiting from the inside.
The Lightbulb Moment
By the third session, the group was deep into the architecture of the tool: what competencies to assess, how to structure them across levels, how to account for the gap between what people say they can do and what they actually can.
The critique of existing frameworks came from Gillies who described the SHRM competency model as "very traditional and very backward-facing in some aspects." The profession was still, in her phrase, in a "post-industrial hangover"—compliance-based, hierarchical, designed for a world that was already receding.
Their tool needed to orient toward something else, not what HR leaders needed to know, but what they needed to be capable of doing.
Are you willing to have a conversation with the CEO about his performance? If you are not, you are not an expert in difficult conversations.
Erin Turnmeyer · VP of People Operations
Turnmeyer had a crystallizing example. She'd recently taken the SPHR exam. The things it required her to know—statutes, procedural definitions, classification rules—were things any competent HR professional would simply look up.
The hard skills weren't the certification material. They were things like: Can you sit across from a CEO and tell him something he doesn't want to hear? Can you advocate for an employee when the business case is ambiguous? Memorizing labor codes does not answer those questions.
Fisher pushed further. He'd spent years in change management, and he'd found that the most predictive variable in an organization's ability to navigate transformation wasn't any specific skill. It was a person's relationship with ambiguity.
Getting out of somebody how comfortable they are with being uncomfortable—or with pace of change in general—is such an indicator of your ability to function in this new world.
Tim Fisher · Head of AI , Black and White Zebra
Then came what the group would later call the secret sauce.
Gillies floated a question. What if the tool built in a cross-check? If someone rated themselves as an expert in conflict management, but then in a natural language response to a follow-up prompt described situations that sounded like anything but expertise, could the AI flag that? Could it say, gently, there might be a gap here?
"That's the light bulb moment," Turnmeyer said.
Satterfield noted that anyone who has worked with skills inventories has seen versions of the same problem. People often rate themselves very differently than their actual experience or behavior would suggest.
The tool's value wouldn't come from recording what people believed about themselves. It would come from the calibration—the gentle, data-informed friction between self-perception and demonstrated capability.
The assessment wouldn’t just be a mirror. It would be more “mirror, mirror on the wall” than most people are used to from workplace assessments.
The Realities of Building
None of this was easy. And the cohort knew that going in.
The most persistent challenge wasn't technical. It was scope. Every session generated ten new directions, each genuinely valuable, each capable of swallowing the project whole. Turnmeyer named it early and named it often.
"Make sure it does the first thing right, so you don't get so scope-creepy you can't create it," she said.
Satterfield introduced a guiding principle for the group: the difference between a Minimum Viable Product and a Minimum Valuable Product. A viable product works. A valuable product makes people want to return.
In a market saturated with assessment tools, an interface that doesn't deliver something meaningful in the first interaction won't get a second chance to improve. The bar isn't functionality. It's worth.
If the product doesn't provide enough value at first entry, users likely aren't coming back later to see if it's gotten any better.
Kelly Satterfield · HR Leader and Consultant
There were also the practical constraints that anyone who has tried to build outside a development team knows well: deployment, payment infrastructure, integration with existing systems, context windows that close mid-session and erase hours of productive work.
The early build reflected the tool's core flow. A candidate for a recruiter role uploads a resume, the tool infers a preliminary skill profile, and then walks them through a series of conversational questions designed to calibrate and add context and depth to that initial read.
At the end, a hiring leader gets a picture of where the candidate actually stands against a defined competency framework.
Fisher set up the primary build environment in Lovable—a no-code AI builder that generates public-facing tools through conversation, without locking users into a specific LLM—so that the technical architecture could keep pace with the group's thinking without becoming its own bottleneck.
From Blueprint to Build
By the fourth session, the group was no longer designing an abstract tool. They were building one and discovering, as builders always do, that the distance between the idea and the execution is precisely where the real learning happens.
Fisher had assembled a base-level custom GPT before the call loaded with instructions, a preliminary competency framework, and the beginnings of the conversational logic they'd mapped in earlier sessions. The plan was for everyone to access it, prompt it collaboratively, and start calibrating its voice and behavior in real time. The plan immediately ran into reality.
The shared link didn't work for anyone but me. Workspace permissions, platform quirks, and the particular way ChatGPT handles external access ate the first quarter of the session.
It was a small frustration, precisely the kind that would never make it into a product announcement and it was instructive. Tools that practitioners actually use to build things don't behave like demos.

This screenshot shows what the welcome screen would come to look like for the tool the group built, called Talent Scout.
Once everyone was looking at the same screen, something more interesting happened. While the group was still talking through what format the competency definitions should take, Gillies opened Claude in a separate window and converted the scoring table into structured JSON—live, on the call.
"I use Claude because it's better than ChatGPT for this," she said, without ceremony. She dropped the formatted file into the group chat minutes later. Nobody stopped to acknowledge it. They just moved forward.
That kind of in-motion problem-solving—turning a bottleneck into a solved problem without making it the meeting's main event—is what distinguishes practitioners who have genuinely internalized these tools from those still learning to navigate them.
Who Gets the Final Say
Satterfield raised a question that would have significant implications for both the tool's architecture and its eventual reception: does the AI render the final rating, or does the user confirm it?
The distinction isn't cosmetic. If the tool delivers a verdict such as "Based on your responses, you are at Level 2 in candidate focus", then it positions the AI as the authority. If it instead surfaces a provisional read and invites the user to push back, the dynamic changes entirely. The assessment becomes collaborative rather than evaluative. The user is a participant in the process, not a subject of it.
"Do you accept this feedback?" Turnmeyer said, as the idea landed. "Kind of love it."
Gillies built out the logic. If the user doesn't accept the rating, the tool asks what feels off—and then uses the response to either recalibrate or gently reconfirm its read, walking through the evidence.
That conversational back-and-forth is what creates the psychological safety the tool needs to be genuinely useful. People don't change based on feedback they don't trust. Getting buy-in isn't a soft feature, it's the mechanism.
The First Real Test
They decided to test the prototype live. Turnmeyer volunteered a deliberately thin answer to one of the assessment questions—the kind a disengaged candidate or distracted employee might give.
She described arguing with her manager over a salary discrepancy, losing the candidate, and having no idea what the outcome had been. It was the HR equivalent of answering "I just really love people" when asked why you want to work in HR.
The tool assessed it immediately. It assigned a level. It was encouraging. It was also wrong, not factually, but premature. It had made assumptions about what the answer implied rather than asking for the additional context it would need to assess accurately.
If you're going to give anybody anything other than 'meets expectations,' you must give detailed examples. The AI should hold itself to the same standard.
Erin Turnmeyer · VP of People Operations
Turnmeyer drew the parallel directly from her performance review practice. She'd long required managers to provide specific evidence before rating anyone above or below "meets expectations."
The same discipline should apply to the tool. Before assigning a level, earn the right to do so by asking the questions that would make the rating defensible. It was, again, the HR expertise in the room making the AI better—not the other way around.
Satterfield added a complication the tool had glossed over. The thin answer might have reflected policy rather than skill.
If the manager had genuinely set a fixed compensation ceiling, advocating harder wouldn't have changed the outcome. The tool had assessed the person when it should have been asking about the situation. Clarifying questions weren't a polish item. They were the thing that would separate a useful assessment from a presumptuous one.
Turnmeyer took the instruction-writing task as homework: how do you prompt a tool to ask clarifying questions at the right moments without making every interaction feel like an interrogation?
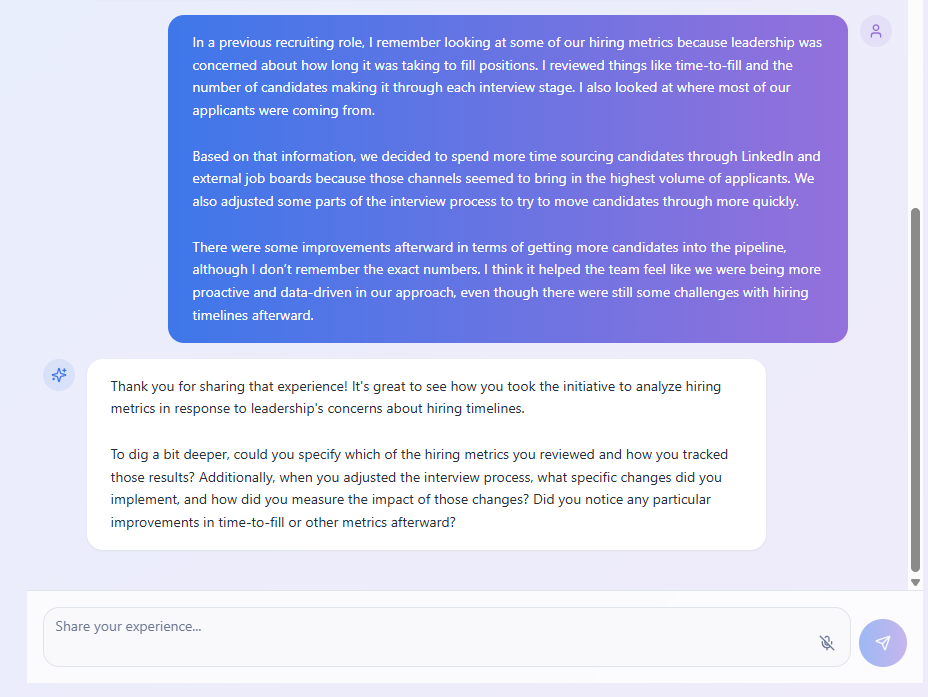
This screenshot shows an example of what the final product would do, asking clarifying questions and pushing the candidate to go into greater depth.
It's a harder problem than it sounds, and she was acutely aware that the bar was unusually high.
"It needs to be better than a human," she said. "That's the standard."
Testing as a Discipline
The session also produced one of the more practically useful methodological insights of the entire cohort. When Satterfield asked how the group typically tested tools like this, both Turnmeyer and Gillies answered in ways that revealed something important about what rigorous testing actually looks like in practice.
For her benefits recommendation tool, which had to accurately surface whether specific medications were covered under the company's health plan, Turnmeyer tested specifically for the edge cases. Not the obvious drugs, the popular ones the model would have encountered repeatedly in training. She tested the obscure ones, in the categories most likely to produce a confident hallucination.
"I went and tested for the not popular drugs," she said, "because Claude showed me what it was doing as it built it."
That level of adversarial intentionality in testing is rare for builders coming from outside an engineering context. It is also exactly what separates tools that gain trust from tools that get quietly abandoned after an embarrassing failure.
Cutting What You've Already Built
A regroup session just before the holidays started with a question that was harder to ask than it sounds: what's the resume upload feature actually for?
Gillies raised it. The assessment asked users to think carefully about their own capabilities. Did the resume add information the user couldn't provide more directly, by just answering the questions? No one in the group was sure it did. The original intent had been to save time, like a resume parser, but we were no longer convinced that it delivered on that.
They agreed to cut it.
This is rarer than it sounds in product development. The group had spent real time on the upload feature—building it, testing it, watching Satterfield's resume get parsed and mis-scored. Cutting it required overriding the sunk cost logic that keeps teams adding to things they've already invested in.
Begin with the end in mind, and define what good looks like for the result. If you can't articulate what a feature is for, you can't defend it.
Turnmeyer made a related argument about methodology. In retrospect, she thought they might have moved faster by fully defining the tool's behavior before writing a single prompt. They'd been running something like an agile model—build, test, adjust—when the complexity of what they were building might have called for more of a waterfall approach: get the spec right first, then build to it.
She had a 130-page design document from a different tool she'd built that had taught her this lesson. A complete spec doesn't just tell you what to build. It tells you what you're not building, which turns out to be equally useful.
Gillies sharpened the product's core problem. Whatever the tool showed on screen needed to go further. An assessment that surfaces data is not the same as a tool that tells you what to do with it. That gap between output and action is where diagnostic tools quietly stop being useful, and it's the gap most of them never close.
Building Alone
By January, Satterfield had been doing most of the building herself as the rest of the group found the pull of their 9-to-5 too strong, too time consuming to leave any room left for the project. After all, no one was being paid for this.
She'd removed the resume upload, as the group had agreed. She'd added voice input—users could now answer assessment questions by speaking rather than typing, which opened up a more conversational response style that was harder to game than a text field.
She'd been using ChatGPT to generate synthetic test responses ("I'm a junior recruiter that's strong in this and weak in this, give me answers"), then switching to Lovable to feed those responses in and observe how the tool scored them.
The leader dashboard was the other half of the tool's logic—the view a TA director or CHRO would use to see how a candidate had scored, where the gaps were, and how their capabilities might complement the strengths and needs of an existing team.
That made organizational structure a real problem because the tool needed to know who was assessing whom, and who had the standing to see the results.
Satterfield had tried to handle this by asking users to enter their name, job title, and manager's name (in the absence of a data integration). But that logic broke for a common scenario: a director of talent acquisition who wanted to send the assessment across a broader recruiting organization that included both direct and indirect reporting relationships. The org mapping logic wasn’t nuanced enough to account for that structure.
In theory, this information would give the tool greater context into the role of the assessment taker, but collecting more data made things more complicated.
Turnmeyer had already solved a version of this problem in a different context. The performance management tool she'd built for her own company ran on Google Sheets, Slack, and Claude. Google Sheets stored the data. Slack was the interface employees interacted with. Claude handled the analysis and feedback generation.
The architecture was simpler than it sounded: a spreadsheet with name, email, job level, job title. A separate tab cross-referencing job level to competencies.
"Security in my company wanted to review my tool," she told the group. "I said it was stored in Google Docs. They went, 'Oh, it's that simple.'"
Simple, but Turnmeyer only learned it by building. The thing she hadn't known three weeks earlier was that logging existed—a function that saves a user's progress so the tool doesn't reset when someone steps away and comes back.
I was swearing at Claude," she said, "until it told me logging existed.
That's what building actually teaches. Not the thing you planned to learn, but the thing you didn't know you needed to know.
The Question Underneath
Somewhere in the January session, the conversation arrived at the question it had been circling for months.
The group kept discussing architecture, permissions, storage, dashboards—real problems, all of them. But underneath them was a more fundamental one. What were they actually trying to build, and for whom?
The tool, as originally conceived, was a selection diagnostic—something a TA leader could send to a candidate or internal employee to assess whether their actual capabilities matched what was on their resume, and surface that picture before a selection decision was made.
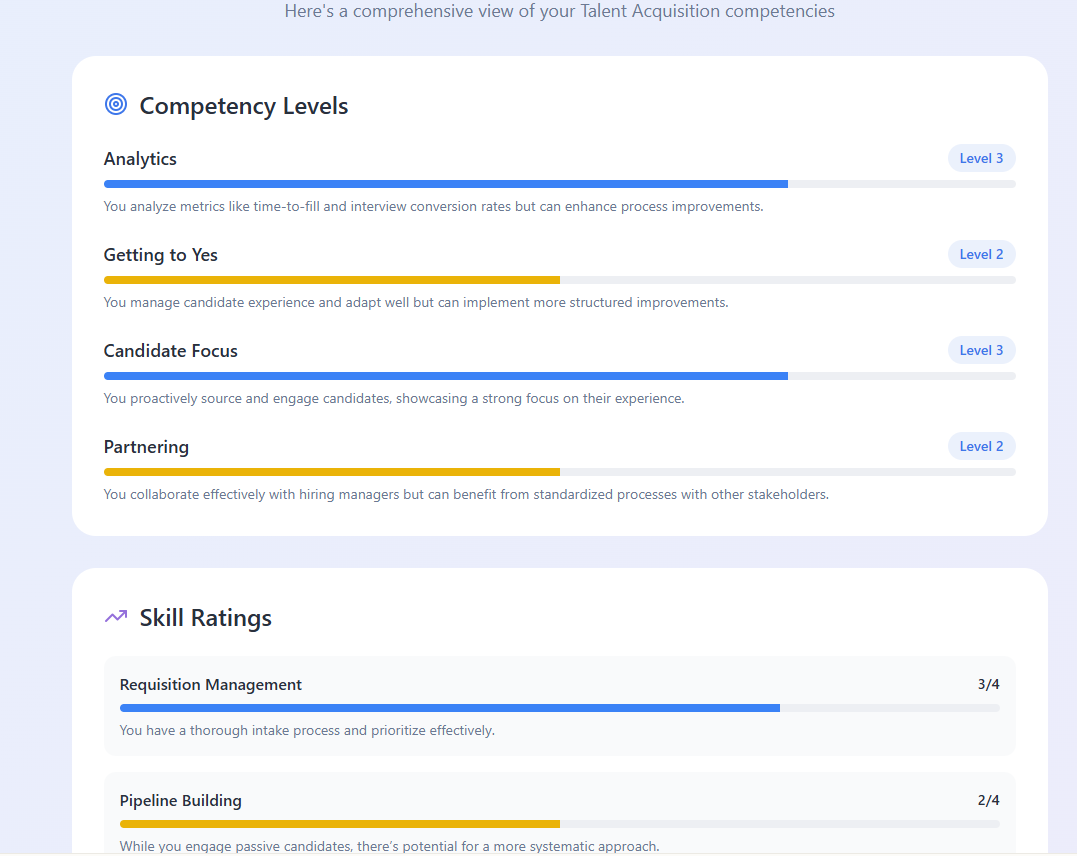
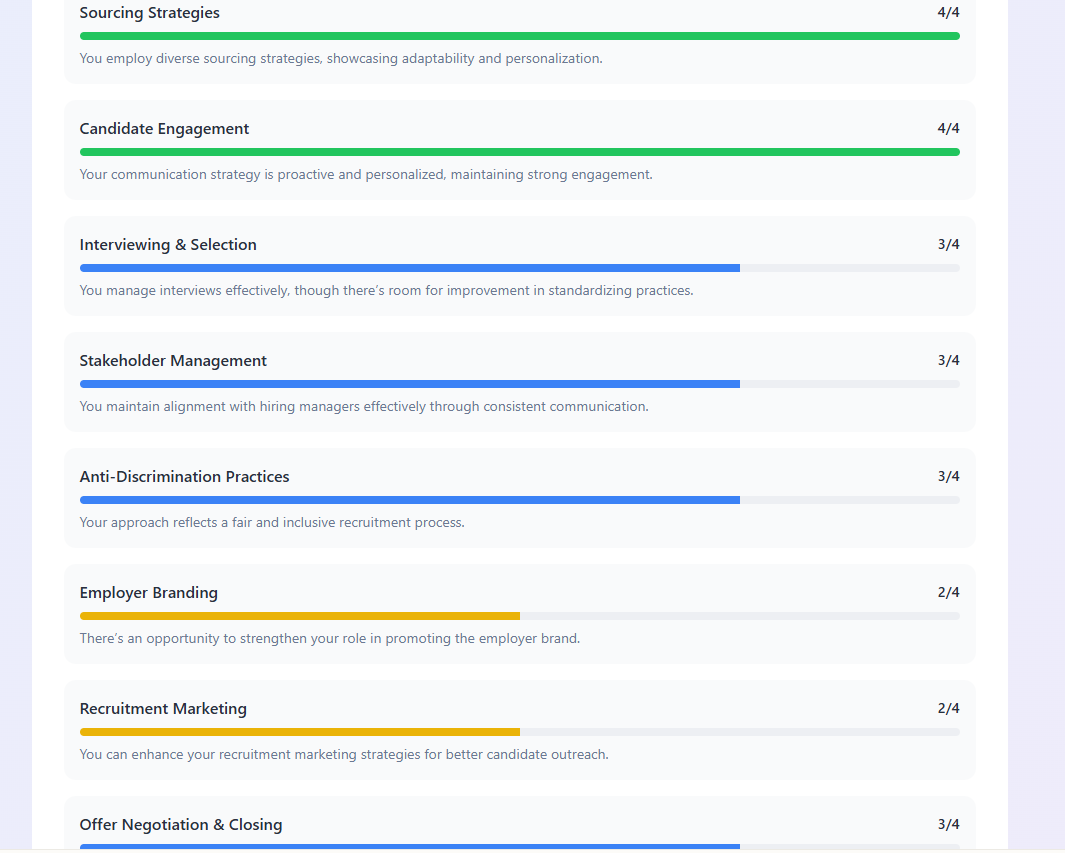

What you see here is a selection of screenshots of the type of report the tool produced for the interviewee. For the assessor, a dashboard of current team strengths helps them focus on where to assess the interviewee to see if they address TA team weaknesses.
That core hadn't changed. But every practical decision they'd been making—adding a leader dashboard, thinking through subscription models, working out a sign-in flow—was pulling them toward something more complex.
Real-time dashboards meant ongoing access, which meant subscription fees, which meant drifting closer to the kind of enterprise tooling many organizations struggle to afford or operationalize effectively.
"We’re not trying to become an HCM vendor," Satterfield said.
Turnmeyer was honest about where she stood.
"My intent was just to learn something new."
That wasn't a retreat from the project. It was an accurate account of what the experiment had already produced for her. She'd learned some new things and was already in progress building a new performance management tool with the lessons from the cohort applied.
She didn't need to productize the group's tool to have gotten real value from it.
At this stage, my own interest was primarily editorial. I wanted a story to tell and something people could view, not a subscription product, but a demonstration that HR practitioners could think about and maybe build one like it.
Writing this article was part of it. Could I make a downloadable guide? Eventually, a live event where the group could discuss what they'd done, let an audience interact with the tool, and record the conversation as a podcast? I had a lot of ideas, but the runway for executing them as the goals of the new year piled up in front of all of us was getting shorter.
Satterfield's interest was the most commercially oriented, and she was clear about it. She was interested in productizing it eventually. She wasn't going to do it alone. But she was willing to keep building toward something that could one day be sold.
That three-way divergence of intent—learning, storytelling, product—is probably inherent to any cohort like this. The honest conversation about it, in January, was more useful than pretending everyone had always wanted the same thing.
The Demo as Answer
The question of how to let people try the tool had been sitting unresolved since the resume upload went live. Testing with real users is valuable, but it creates its own problems. The tool needs to work consistently, users need enough context to know what they're doing, and a bad first experience is hard to recover from.
Turnmeyer offered the simplest resolution the group had considered.
She'd been watching demo recordings—short walkthroughs, a minute or two, showing how a tool worked without requiring the viewer to actually use it. She suggested that might be enough. People could see the tool in action, understand what it was doing and why, and leave feeling like it was possible.
They wouldn't need to navigate a login, supply an org chart, or get stuck when an assessment question didn't match their situation.
The feedback I get from a lot of the blogs I write is that people don't really want to copy-paste exactly the same thing. They just want to know they're able to do it.
Erin Turnmeyer · VP of People Operations
That observation points at something real about how HR practitioners are relating to AI tools right now. The gap many of them are navigating isn't between knowing something exists and using it. It's between believing they're capable of doing something like this at all.
A demo showing practitioners building their own tool answers a different question than a finished product does—not "is this tool good?" but "could someone like me have made it?"
The idea was well received. It addressed the testing concerns, reduced the complexity of sharing something that wasn't production-ready, and kept the emphasis where the cohort had always meant it to be, on the process and the thinking, not just the output.
What the Experiment Taught: A Guide for HR Builders
- Start with the problem, not the technology. The group's early enthusiasm for sentiment analysis was genuine and it led them away from a more tractable, more valuable problem. The pivot to skills mapping worked because it started with a real use case that had already been tested in the field.
- Bespoke beats generic. Every participant had encountered the limits of enterprise HR platforms. The tools built for specific contexts—Turnmeyer's benefits recommender, Satterfield's heat map—outperformed the off-the-shelf alternatives. The case for building your own is stronger than it's ever been, and the barriers are lower.
- The cross-check is the whole game. Self-assessments are only as good as people's self-knowledge, which is famously unreliable. A tool's real value lies in its ability to probe, challenge, and gently recalibrate—not merely record what people believe about themselves.
- Minimum Valuable, not Minimum Viable. If the first version doesn't deliver something that makes a user want to return, the roadmap doesn't matter. Design for the first impression, not the fifth.
- Buy-in is structural, not soft. The question of whether the AI renders the final rating or the user confirms it isn't a UX detail. It determines whether the tool is an authority or a collaborator and that distinction shapes everything about how it gets received and used.
- Cut features you've already built. Sunk cost logic keeps teams adding to things they've invested in long after those things have stopped earning their place. If you can't articulate what a feature is for, that's your answer. Cutting it is product discipline, not failure.
- Test adversarially, and early. Find people who will tell you the tool is bad. Give it the worst reasonable input you can imagine and see what it does. Build in the edge cases before you polish the typical ones. The tool's credibility depends on how it handles the moments it wasn't designed for.
- The tool should earn the right to assess. Jumping to a rating before asking enough questions is presumption, not efficiency. Clarifying questions are what make the assessment defensible, and defensibility is what makes feedback stick.
- Be honest about what everyone's there for. Divergent intentions within a group aren't a problem to be managed—they're information. Getting them on the table early saves everyone from building toward a goal that only some of them actually share.
- The hardest conversations are the most important ones. The cohort built a tool to assess HR skills, and in doing so, had one of the most honest conversations about HR's limitations that any of them could remember. That conversation—about backward-facing frameworks, about the gap between exam knowledge and situational judgment—was the product as much as the tool.
The sessions that began as a four-call commitment stretched into winter, then into the new year. The prototype was still evolving. The intentions of the people who'd built it had clarified in ways that didn't resolve neatly.
Satterfield was still building. Turnmeyer had taken what she'd learned and applied it elsewhere. Gillies had pushed the group to be more disciplined about what the tool was actually supposed to do. I was writing the story of all of it.
Turnmeyer had said something early in the process that stayed true: she was building not because she'd been asked to, but because she needed to understand.
That understanding of what AI tools actually do, what they get wrong, what it takes to make them useful, wasn't available in any conference session or vendor demo. It came from the decisions the group made, the features they cut, the moments when the tool assessed someone incorrectly and they had to figure out why.
The most useful things the cohort produced weren't in the prototype. They were in the reasoning behind it.