{kind=link}
Wenn HR-Führungskräfte zu Gestaltern werden

Erkenntnisse aus dem Experiment: Kollaborative KI-Projekte lieferten tiefe Einblicke in HR-Kompetenzen, die über die reine Tool-Entwicklung hinausgehen.
Fokus auf das Problem: Der Wechsel von Sentiment-Analyse zu Kompetenzzuordnung zeigte, wie wichtig klar definierte und machbare Ziele sind.
KI-Skepsis: HR-Profis stehen bei bestehenden KI-Plattformen vor großen Herausforderungen rund um Verantwortlichkeit und Nachvollziehbarkeit.
Tool-Struktur: Das KI-Bewertungstool stellte Zusammenarbeit in den Vordergrund und ermöglichte Benutzer:innen, KI-generiertes Feedback zu bestätigen oder zu hinterfragen.
Adversarial Testing: Für eine erfolgreiche Tool-Entwicklung ist rigoroses Testen mit diversen Eingaben unerlässlich, um Spezialfälle gezielt abzudecken.
Die Meetings waren für eine Stunde angesetzt. Sie dauerten fast immer länger.
Das ist nicht ungewöhnlich, wenn sich eine Gruppe von HR-Profis trifft, um über KI zu sprechen. Ungewöhnlich war jedoch, was mit diesem Gespräch getan werden sollte. Nicht analysieren, keinen Artikel dazu veröffentlichen, sondern tatsächlich etwas bauen.
Im Herbst 2025 stellte ich sogenannte Builder-Kohorten zusammen: eine kleine Gruppe von Fachleuten aus HR und People Operations, die ich als bereits aktive Gestalter identifiziert hatte und die schon an den Grenzen von dem, was der HR-Beruf mit KI leisten kann, dachten.
Die Hypothese war einfach: Diejenigen, die den Problemen am nächsten sind, sind auch am besten positioniert, um die Lösungen zu entwickeln. Die Frage war, ob sie das könnten.
Insgesamt würde ich vier Kohorten bilden und dabei feststellen, dass es leichter gesagt als getan ist, Ziele für diese Sitzungen festzulegen. Am Ende liefen die meisten Kohorten im Sande, kämpften damit, die ursprüngliche Vision zu verwirklichen oder sich auf ein gemeinsames Ziel zu einigen. Kalender, Arbeitsbelastungen, die Anforderungen unserer eigentlichen Arbeit führten oft zu Gesprächen, aus denen großartige Ideen hervorgingen, die aber nie umgesetzt wurden.
Aber eine Kohorte hielt tatsächlich so gut es ging bis zum Schluss zusammen. Tatsache ist: Je tiefer man in den Do-it-yourself-Bau abtaucht, desto schwieriger wird es, eine gemeinsame Vision zu bewahren und die technische Herausforderung zu meistern.
Diese Geschichte berichtet von den Ergebnissen dieser Sitzungen und soll Ihnen als Fallstudie zum Aufbau eigener Lösungen dienen.
Die Kohorte




Dies waren keine KI-Skeptiker, die noch überzeugt werden mussten. Sie waren Praktiker, die bereits auf diesen Moment gesetzt hatten. Die Kohorte bot ihnen einen strukturierten Raum, um mit dem Beraten aufzuhören und mit dem Machen zu beginnen.
Das erste ehrliche Gespräch
In der ersten Sitzung wurde etwas angesprochen, das in veröffentlichten HR-Kommentaren selten Platz findet: Wie frustriert diese Profis tatsächlich von den Tools sind, die sie benutzen sollen.
Turnmeyer gab den Ton an. Sie hatte versucht, technische Dokumentationen darüber zu erhalten, wie die Sentimentanalyse in BambooHR, Paycom und Gusto funktionierte – nicht, um die Tools zu kritisieren, sondern weil ihr Rechtsteam vor der Freigabe deren Funktionsweise verstehen musste.
Weder das Vertriebsteam noch die Rechtsabteilung konnten ihre Fragen beantworten. Die KI-Funktionen existierten. Die Verantwortlichkeit dafür, wie sie funktionierten, jedoch nicht.
Gillies stand vor einer ähnlichen Herausforderung. Intern wurden Bedenken hinsichtlich der Umweltfolgen von KI geäußert und einige Kollegen wollten die Nutzung von KI durch Mitarbeitende einfach verbieten. Gillies setzte sich dagegen ein.
Das vollständige Verbot von KI führt zu verdeckter Nutzung und erhöhtem Risiko. Ein konstruktiver Umgang mit KI, kombiniert mit Leitplanken, ist der bessere Weg.
Melina Gillies · Chief of People, Flex Networks
Was sich nach dieser ersten Stunde herauskristallisierte, war eine Diagnose, auf die sich die Gruppe einigen konnte. Die integrierten KI-Funktionen von Enterprise-HR-Plattformen waren, wie Gillies es formulierte, „oft schlicht gehalten und bieten wenig Funktionalität“.
Die Werkzeuge, die tatsächlich funktionieren, sind meist maßgeschneidert – entwickelt für spezifische Probleme, spezifische Kontexte, spezifische Unternehmen. Turnmeyer wünschte sich weniger Tools statt mehr, ein Wunsch, der mir häufig von Personal- und Operationsleiter:innen begegnet. Sie stellte sich eine Zukunft vor, in der eine leistungsfähige KI, gut gefüttert mit den richtigen Dokumenten, ein HRIS überflüssig machen könnte.
Die Gruppe sprach auch ein Thema an, das selten so offen thematisiert wird: die Ethik des Verhaltensmonitorings. Schon früh kam die Idee auf, Meeting-Ablehnungsquoten, Lücken bei Systemanmeldungen oder ungewöhnliche Arbeitszeiten als Indikatoren für geringe Bindung zu nutzen.
Auch die Grenzen dieses Ansatzes waren Thema. Satterfield benannte ein Risiko, dem sich jedes Engagement-Tool irgendwann stellen muss: Handlungsmüdigkeit. Wenn Daten gesammelt, aber keine sichtbaren Konsequenzen gezogen werden, verlieren die Mitarbeitenden das Vertrauen ins System. Die Daten werden zu Hintergrundrauschen und das Tool verkommt zum KI-Theater.
Sie waren noch nicht bereit, ein Tool zur Sentiment-Analyse zu bauen. Das Feld war zu breit, zu aufgeladen mit ethischen Fragestellungen und zu riskant, um katastrophale Fehler zu vermeiden. Also überlegte die Gruppe um.
Das richtige Problem finden
Die zweite Sitzung begann mit dem ehrlichen Eingeständnis, dass die ursprüngliche Richtung zu ehrgeizig und zu unkonkret war.
„Ich weiß nicht, ob das Bindung misst“, sagte Turnmeyer, „oder nur etwas, das eigentlich ein Gespräch erfordert.“
Diese Unterscheidung ist wichtiger, als es zunächst klingt. Viele HR-Technologien machen den Fehler, Daten als Ersatz für Gespräche zu betrachten. Die Gruppe wollte KI so einsetzen, dass sie Momente erkennt, in denen ein Gespräch notwendig ist, und dann dieses Gespräch verbessert.
Satterfield brachte die Idee ein, die das weitere Projekt bestimmen sollte. Während eines Einstellungsstopps bei ihrer früheren Firma hatte sie eine Selbsteinschätzung der Kompetenzen für ihr Recruiting-Team erstellt – eine Methode, um abzugleichen, was Mitarbeitende können und was sie tatsächlich tun wollen. Daraus entstand eine Heatmap, die Umverteilungsentscheidungen menschlicher und strategischer machte.
Das war nicht KI-basiert. Es war ein Microsoft-Formular. Aber die zugrunde liegende Logik war stimmig, der Anwendungsfall real – und sie hatte erlebt, dass es funktionierte.
„Die großen Anbieter versuchen das zwar, aber niemand macht es richtig gut, und viele Firmen haben für diese Art von Technologie kein Budget zusätzlich zu ihrem Kern-HRIS“, sagte sie.
Die Gruppe erkannte ihre Chance. Was, wenn sie eine KI-native Version entwickelten? Eine, die auf Dialog statt auf Diagnostik setzt, die nach vorne schaut statt nur auf Compliance, und die auf einzelne HR-Leiter:innen zugeschnitten ist, statt hinter teuren Enterprise-Verträgen verborgen zu sein?
Die Art, wie HR mit HR über HR spricht, ist dynamisch anders. Darin liegt echter Mehrwert und die meisten Tools übersehen das komplett.
Melina Gillies · Chief of People, Flex Networks
Fisher, der zuhörte, während die Gruppe die Möglichkeiten auslotete, machte eine Beobachtung, die das Potenzial des Projekts in neuem Licht erscheinen ließ. Er hatte beide Enden des HR-Spektrums erlebt: den Compliance-orientierten, Framework-basierten, transaktionalen Typ und die selteneren Menschen-orientierten Praktiker:innen, die mit ihm „wie jemand gesprochen haben, der auf meiner Seite steht“.
„Die Sprache der zweiten Sorte“, sagte er, „klang nie nach einem Leitfaden aus einer vergangenen Zeit. Es fühlte sich einfach gut an.“
Gillies griff das auf. Der Unterschied ihres Tools, so argumentierte sie, sollte Ton und Struktur sein. Was, wenn es den Austausch von HR-Fachleuten wie auf einer Konferenz, zwischen den Sessions, abbilden könnte – offen, informell, zwischen den Zeilen? Was, wenn es „politische Cleverness“ nicht als Ja/Nein-Kästchen, sondern als komplexe, diskussionswürdige Qualität begreift, über die erfahrene Profis untereinander streiten?
Das war die neue Richtung: Ein Pre-Hire-Assessment-Tool speziell für HR- und Recruiting-Leiter:innen, die eine bessere Methode suchen, um Recruiter-Kandidat:innen vor der Einstellung zu beurteilen. Kein Persönlichkeitstest oder Screening von Lebensläufen, sondern eine strukturierte, dialogorientierte Diagnose, die Führungskräften wirklich sagt, ob die Person gegenüber den Job beherrscht. Ein Tool, das weniger wie ein Leistungsbericht und mehr wie ein Fachgespräch mit Insiderverständnis wirkt.

Der Aha-Moment
In der dritten Sitzung tauchte die Gruppe tief in die Architektur des Tools ein: Welche Kompetenzen sollen bewertet werden, wie lassen sich diese über verschiedene Erfahrungsstufen strukturieren und wie berücksichtigt man die Differenz zwischen Selbsteinschätzung und tatsächlichem Können?
Die Kritik an existierenden Frameworks kam von Gillies, die das SHRM-Kompetenzmodell als „sehr traditionell und in manchen Aspekten rückwärtsgerichtet“ bezeichnete. Die Profession stecke, so ihre Formulierung, noch im „postindustriellen Kater“ – Compliance-basiert, hierarchisch, erschaffen für eine Welt, die längst vergeht.
Ihr Tool musste sich auf etwas anderes ausrichten, nicht darauf, was HR-Führungskräfte wissen mussten, sondern was sie tatsächlich zu tun imstande sein sollten.
Sind Sie bereit, ein Gespräch mit dem CEO über seine Leistung zu führen? Wenn nicht, sind Sie kein Experte für schwierige Gespräche.
Erin Turnmeyer · VP of People Operations
Turnmeyer hatte ein prägnantes Beispiel. Sie hatte kürzlich die SPHR-Prüfung abgelegt. Was dort verlangt wurde – Gesetze, formale Definitionen, Klassifizierungsregeln – waren Dinge, die jeder kompetente HR-Professional einfach nachschlagen würde.
Die harten Fähigkeiten waren nicht der Prüfungsstoff. Es ging vielmehr darum: Können Sie dem CEO gegenübersitzen und ihm etwas sagen, was er nicht hören will? Können Sie für einen Mitarbeitenden eintreten, wenn der geschäftliche Nutzen unklar ist? Das Auswendiglernen von Arbeitsgesetzen beantwortet diese Fragen nicht.
Fisher ging noch einen Schritt weiter. Nach Jahren im Change Management hatte er festgestellt: Die Fähigkeit einer Organisation, Veränderung zu meistern, hing nicht von einzelnen Kompetenzen ab. Entscheidend war die Beziehung einer Person zur Ungewissheit.
Herauszufinden, wie wohl sich jemand im Unwohlsein fühlt – oder mit Veränderungstempo generell –, ist ein enormer Indikator für die Fähigkeit, in dieser neuen Welt zu funktionieren.
Tim Fisher · Head of AI , Black and White Zebra
Dann kam, was die Gruppe später als das Geheimrezept bezeichnete.
Gillies stellte eine Frage in den Raum. Was, wenn das Tool einen Quervergleich einbauen würde? Wenn sich jemand als Experte für Konfliktmanagement einstufte, aber dann in einer freien Antwort auf eine Nachfolgefrage Situationen beschrieb, die alles andere als Expertise erkennen ließen, könnte die KI das markieren? Könnte sie sanft sagen, dass es hier vielleicht eine Lücke gibt?
„Das ist der Geistesblitz-Moment“, sagte Turnmeyer.
Satterfield merkte an, dass jeder, der schon mit Skill-Inventuren gearbeitet hat, das Problem kennt. Menschen bewerten sich oft ganz anders, als es ihre tatsächliche Erfahrung oder ihr Verhalten vermuten lässt.
Der Wert des Tools würde nicht darin liegen, festzuhalten, was die Menschen über sich selbst glauben. Er entstünde aus der Kalibrierung – aus der sanften, datenbasierten Reibung zwischen Selbstwahrnehmung und tatsächlich gezeigter Fähigkeit.
Das Assessment wäre nicht bloß ein Spiegel. Es wäre eher „Spieglein, Spieglein an der Wand“ als das, woran Menschen von Assessments am Arbeitsplatz gewöhnt sind.
Die Realitäten des Aufbauens
All das war nicht einfach. Und das wusste die Gruppe von Anfang an.
Die beharrlichste Herausforderung war nicht technischer Natur. Es war die Reichweite. Jede Sitzung brachte zehn neue Richtungen hervor, jede für sich wertvoll und jede dazu in der Lage, das Projekt zu verschlingen. Turnmeyer benannte das früh und häufig.
„Sorgt dafür, dass es die erste Sache richtig macht, damit ihr nicht so vom Umfang abkommt, dass ihr es nicht mehr umsetzen könnt“, sagte sie.
Satterfield brachte ein Leitprinzip für die Gruppe ein: der Unterschied zwischen Minimum Viable Product und Minimum Valuable Product. Ein nutzbares Produkt funktioniert. Ein wertvolles Produkt sorgt dafür, dass Menschen wiederkommen.
In einem Markt voller Assessment-Tools wird eine Oberfläche, die schon beim ersten Kontakt keinen echten Mehrwert bietet, keine zweite Chance zur Verbesserung bekommen. Die Messlatte ist nicht die Funktionalität. Es geht um den Wert.
Wenn das Produkt beim ersten Einstieg nicht genug Mehrwert stiftet, kommen Nutzer später wohl kaum zurück, um zu sehen, ob es besser geworden ist.
Kelly Satterfield · HR Leader und Beraterin
Es gab auch die ganz praktischen Herausforderungen, die jede:r kennt, der/die außerhalb eines Entwicklerteams etwas bauen will: Deployment, Zahlungsinfrastruktur, Integration bestehender Systeme, Kontextfenster, die sich mitten in der Session schließen und produktive Arbeit zunichte machen.
Der frühe Prototyp spiegelte den Kernablauf des Tools wider. Ein:e Bewerber:in für eine Recruiter-Rolle lädt einen Lebenslauf hoch, das Tool erkennt daraus ein vorläufiges Kompetenzprofil und stellt dann eine Reihe von Gesprächsfragen, um diesen Ersteindruck zu kalibrieren und mit Kontext und Tiefe zu versehen.
Am Ende erhält eine Führungskraft ein Bild davon, wo der/die Kandidat:in tatsächlich im Hinblick auf einen definierten Kompetenzrahmen steht.
Fisher richtete die grundlegende Entwicklungsumgebung in Lovable ein – einem No-Code-AI-Builder, der durch Gespräche öffentlich nutzbare Tools erstellt, ohne die Nutzer an ein bestimmtes LLM zu binden –, sodass die technische Architektur mit dem Denken der Gruppe Schritt halten konnte, ohne selbst zum Nadelöhr zu werden.
Vom Konzept zum Bau
Bis zur vierten Sitzung entwickelte die Gruppe kein abstraktes Tool mehr. Sie bauten eines und erlebten – wie es allen Erbauer:innen geht –, dass gerade in der Lücke zwischen Idee und Umsetzung das eigentliche Lernen passiert.
Fisher hatte vor dem Anruf einen Basis-GPT mit Anweisungen, einem vorläufigen Kompetenzrahmen und den ersten Ansätzen der Gesprächslogik zusammengestellt, die sie in früheren Sitzungen erarbeitet hatten. Der Plan war, dass alle darauf zugreifen, ihn gemeinsam testen und seine Stimme sowie sein Verhalten in Echtzeit kalibrieren. Der Plan kollidierte jedoch sofort mit der Realität.
Der geteilte Link funktionierte nur bei mir. Arbeitsplatzberechtigungen, Eigenheiten der Plattform und die spezielle Art, wie ChatGPT externen Zugriff handhabt, kosteten das erste Viertel der Sitzung.
Es war eine kleine Frustration, genau die Art, die es nie in eine Produktankündigung schafft – und dennoch lehrreich. Werkzeuge, mit denen Praktiker tatsächlich Dinge bauen, verhalten sich nicht wie Demoversionen.

Dieser Screenshot zeigt, wie der Begrüßungsbildschirm für das Tool aussehen würde, das die Gruppe erstellt hat, genannt Talent Scout.
Sobald alle auf den gleichen Bildschirm blickten, geschah etwas Interessanteres. Während die Gruppe noch diskutierte, in welchem Format die Kompetenzdefinitionen vorliegen sollten, öffnete Gillies Claude in einem separaten Fenster und konvertierte die Bewertungstabelle live während des Gesprächs in strukturiertes JSON.
„Ich nehme Claude, weil es dafür besser ist als ChatGPT“, sagte sie ohne großes Aufheben. Minuten später stellte sie die formatierte Datei im Gruppenchat zur Verfügung. Niemand hielt inne, um es zu würdigen. Alle machten einfach weiter.
Diese Art von problemlösungsorientiertem Handeln – ein Engpass wird im Vorbeigehen gelöst, ohne dass daraus das Hauptthema des Treffens wird – zeichnet Praktiker aus, die diese Werkzeuge wirklich verinnerlicht haben, gegenüber denen, die sie noch zu navigieren lernen.
Wer hat das letzte Wort?
Satterfield stellte eine Frage, die sowohl für die Architektur des Tools als auch für dessen spätere Akzeptanz eine gewichtige Rolle spielen würde: Gibt das KI-Tool die endgültige Bewertung ab – oder bestätigt der Nutzer sie selbst?
Der Unterschied ist nicht nur oberflächlich. Gibt das Tool beispielsweise einen Urteilsspruch wie „Basierend auf Ihren Antworten befinden Sie sich auf Level 2 beim Fokus auf Kandidaten“, positioniert sich die KI als Autorität. Wird hingegen eine vorläufige Einschätzung präsentiert und der Nutzer eingeladen, Einspruch einzulegen, ändert sich die Dynamik grundlegend. Die Bewertung wird kollaborativ statt evaluierend. Der Nutzer ist Teil des Prozesses, nicht bloß Objekt dessen.
„Akzeptieren Sie dieses Feedback?“, sagte Turnmeyer, als die Idee formuliert war. „Mag ich irgendwie.“
Gillies baute die Logik weiter aus. Lehnt der Nutzer die Bewertung ab, fragt das Tool nach, was sich nicht stimmig anfühlt – und nutzt dieses Feedback entweder, um neu zu kalibrieren oder, indem es auf die Belege eingeht, vorsichtig bei seiner Einschätzung zu bleiben.
Gerade dieses dialogische Hin und Her sorgt für die psychologische Sicherheit, die das Tool braucht, um wirklich nützlich zu sein. Menschen ändern sich nicht aufgrund von Feedback, das sie nicht vertrauen. Zustimmung ist kein nettes Zusatzfeature, sondern der eigentliche Mechanismus.
Die erste echte Bewährungsprobe
Sie beschlossen, den Prototypen live zu testen. Turnmeyer bot absichtlich eine dürftige Antwort auf eine der Bewertungsfragen – genau die Art, die ein desinteressierter Bewerber oder abgelenkter Mitarbeiter geben würde.
Sie erzählte, wie sie mit ihrer Führungskraft wegen eines Gehaltsunterschieds gestritten hatte, den Kandidaten verlor und keinerlei Kenntnis über das Ergebnis hatte. Im HR-Umfeld entspricht das etwa der Antwort „Ich mag einfach Menschen total gern“, wenn gefragt wird, warum man im Personalbereich arbeiten möchte.
Das Tool bewertete dies sofort. Es vergab ein Level. Es war ermutigend. Es war aber auch falsch, nicht faktisch, sondern verfrüht. Das Tool hatte Annahmen über die Antwort getroffen, anstatt nach den Kontexten zu fragen, die es für eine korrekte Einschätzung gebraucht hätte.
Wer jemandem etwas anderes als „entspricht den Erwartungen“ bescheinigen will, muss detaillierte Beispiele liefern. Die KI sollte sich denselben Standard setzen.
Erin Turnmeyer · VP of People Operations
Turnmeyer zog die Parallele direkt aus ihrer Praxis bei Leistungsbeurteilungen. Sie hatte schon immer von Führungskräften verlangt, konkrete Belege zu liefern, bevor sie jemanden besser oder schlechter als „erfüllt die Erwartungen“ bewerteten.
Die gleiche Disziplin sollte auch für das Tool gelten. Bevor ein Level vergeben wird, muss es sich dieses Recht durch gezielte Nachfragen verdienen, die die Bewertung begründbar machen. Wieder einmal war es das HR-Know-how im Raum, das die KI verbesserte – nicht umgekehrt.
Satterfield brachte eine Komplikation ein, die das Tool bisher übersehen hatte. Die knappe Antwort hätte eine Richtlinie widerspiegeln können und nicht die Fähigkeiten der Person.
Hätte die Führungskraft tatsächlich eine feste Gehaltsobergrenze gesetzt, hätte energischeres Verhandeln nicht zu einem anderen Ergebnis geführt. Das Tool hatte die Person bewertet, obwohl es eigentlich nach der Situation hätte fragen sollen. Klärende Fragen waren kein Feinschliff, sondern das Unterscheidungsmerkmal zwischen nützlicher und anmaßender Bewertung.
Turnmeyer nahm die Aufgabe der Instruktionsformulierung als Hausaufgabe mit: Wie bringt man ein Tool dazu, an den richtigen Stellen klärende Fragen zu stellen, ohne jede Interaktion wie ein Verhör wirken zu lassen?
Dieser Screenshot zeigt ein Beispiel dafür, was das Endprodukt leisten soll: Es stellt klärende Fragen und fordert die Kandidatin oder den Kandidaten dazu auf, noch mehr ins Detail zu gehen.
Das Problem ist schwieriger, als es klingt, und ihr war sehr bewusst, dass die Messlatte ungewöhnlich hoch lag.
„Es muss besser sein als ein Mensch“, sagte sie. „Das ist der Maßstab.“
Testen als Disziplin
In der Session entstand auch eine der praktisch nützlichsten methodischen Erkenntnisse des gesamten Teams. Als Satterfield fragte, wie die Gruppe üblicherweise Tools dieser Art testet, antworteten sowohl Turnmeyer als auch Gillies auf eine Weise, die Wichtiges darüber verriet, wie rigoroses Testen in der Praxis tatsächlich aussieht.
Für ihr Tool zur Leistungsberatung, das zuverlässig anzeigen musste, ob bestimmte Medikamente im Gesundheitsplan des Unternehmens abgedeckt sind, testete Turnmeyer gezielt die Randfälle. Nicht die offensichtlichen Medikamente, die populären, mit denen das Modell häufig im Training konfrontiert wurde. Sie testete die unbekannten Präparate, in den Kategorien, von denen man am ehesten fälschlich überzeugende Halluzinationen erwartete.
„Ich habe also die unbekannten Medikamente getestet“, sagte sie, „weil mir Claude gezeigt hat, was es während des Aufbaus gemacht hat.“
Dieses Maß an bewusst konträrem Testen ist bei Entwicklerinnen und Entwicklern, die nicht aus dem Ingenieurswesen kommen, selten. Aber genau das trennt Tools, denen man vertraut, von Tools, die nach einem peinlichen Fehler leise wieder abgeschafft werden.
Features streichen, die man schon gebaut hat
Eine neue Abstimmungsrunde kurz vor den Feiertagen begann mit einer Frage, die schwieriger zu stellen war als es zunächst klang: Wozu ist die Lebenslauf-Upload-Funktion eigentlich gut?
Gillies brachte das Thema auf. Die Prüfung forderte die Nutzer dazu auf, genau über die eigenen Fähigkeiten nachzudenken. Ergänzte der Lebenslauf tatsächlich Informationen, die der Nutzer nicht auch direkt durch Beantwortung der Fragen liefern konnte? Niemand in der Gruppe war sicher, dass das der Fall war. Der ursprüngliche Gedanke war gewesen, Zeit zu sparen – wie ein Lebenslauf-Parser –, aber mittlerweile glaubte niemand mehr, dass das so funktionierte.
Sie einigten sich darauf, das Feature zu streichen.
Das ist seltener, als es in der Produktentwicklung klingt. Die Gruppe hatte viel Zeit in das Upload-Feature investiert – es gebaut, getestet, gesehen, wie Satterfields Lebenslauf analysiert und falsch bewertet wurde. Es zu streichen bedeutete, die Sunk-Cost-Logik zu überwinden, die dafür sorgt, dass Teams an Dingen weiterbauen, in die sie bereits viel investiert haben.
Beginne mit dem Ergebnis vor Augen – und definiere, wie ein gutes Resultat aussehen soll. Wenn du nicht klar benennen kannst, wofür ein Feature gut ist, kannst du es auch nicht verteidigen.
Turnmeyer brachte einen methodischen Punkt ein. Rückblickend dachte sie, dass sie womöglich schneller gewesen wären, wenn sie das gewünschte Verhalten des Tools vor dem ersten Prompt vollständig definiert hätten. Sie hatten eine Art agiles Modell gefahren – bauen, testen, anpassen –, obwohl die Komplexität ihres Produkts vielleicht eher nach dem Wasserfallmodell verlangt hätte: Zuerst die Spezifikation richtig hinbekommen und dann daran bauen.
Sie hatte ein 130-seitiges Design-Dokument aus einem früheren Projekt, das sie diese Lektion gelehrt hatte. Eine vollständige Spezifikation sagt dir nicht nur, was gebaut werden soll. Sie sagt dir auch, was du nicht baust – und das ist oft genauso nützlich.
Gillies brachte das Kernproblem des Produkts auf den Punkt. Was auch immer das Tool auf dem Bildschirm zeigte, es musste weitergehen. Eine Prüfung, die nur Daten liefert, ist nicht dasselbe wie ein Tool, das dir sagt, was du damit anfangen sollst. Diese Lücke zwischen Ergebnis und Handlung ist der Moment, in dem Diagnose-Tools leise aufhören, nützlich zu sein – und genau diese Lücke schließen die meisten nie.
Allein weiterbauen
Bis Januar hatte Satterfield den Großteil der Entwicklung selbst übernommen, weil der Rest des Teams kaum noch Zeit neben ihren 9-to-5-Jobs für das Projekt fand. Schließlich wurde ja niemand für die Arbeit bezahlt.
Sie hatte den Lebenslauf-Upload entfernt, wie es die Gruppe beschlossen hatte. Sie hatte eine Spracheingabe eingebaut – Nutzerinnen und Nutzer konnten nun die Prüfungsfragen per Sprache beantworten, was einen dialogorientierteren Stil ermöglichte, der schwerer zu umgehen war als ein Textfeld.
Sie nutzte ChatGPT, um synthetische Testantworten zu erzeugen („Ich bin Junior-Recruiterin, gut in diesem Bereich, schlecht in jenem – gib mir mögliche Antworten“), schaltete dann auf Lovable um und fütterte diese Antworten ein, um zu beobachten, wie das Tool sie bewertete.
Das Leader-Dashboard war die andere Hälfte der Logik des Tools – die Ansicht, die eine TA-Direktorin oder ein CHRO nutzen würde, um zu sehen, wie ein:e Kandidat:in abgeschnitten hatte, wo die Lücken waren und wie deren Fähigkeiten die Stärken und Bedürfnisse eines bestehenden Teams ergänzen könnten.
Das machte die Organisationsstruktur zu einem echten Problem, denn das Tool musste wissen, wer wen bewertet und wer die Befugnis hatte, die Ergebnisse einzusehen.
Satterfield hatte versucht, dies zu lösen, indem sie die Nutzer:innen darum bat, ihren Namen, ihre Berufsbezeichnung und den Namen ihrer Führungskraft einzugeben (in Ermangelung einer Datenintegration). Aber diese Logik funktionierte nicht bei einem gängigen Szenario: Eine Leiterin der Talentakquise wollte die Bewertung über eine größere Recruiting-Organisation mit sowohl direkten als auch indirekten Berichtslinien verteilen. Die Logik zur Abbildung der Organisation war nicht nuanciert genug, um diese Struktur abzudecken.
Theoretisch würde diese Information dem Tool mehr Kontext zur Rolle der bewertenden Person geben, aber das Sammeln weiterer Daten machte die Sache komplizierter.
Turnmeyer hatte eine Version dieses Problems bereits in einem anderen Kontext gelöst. Das Performance-Management-Tool, das sie für ihr eigenes Unternehmen gebaut hatte, lief über Google Sheets, Slack und Claude. Google Sheets speicherte die Daten. Slack war die Benutzeroberfläche für die Mitarbeitenden. Claude übernahm die Analyse und die Erstellung von Feedback.
Die Architektur war einfacher, als sie klang: eine Tabelle mit Name, E-Mail, Joblevel, Berufsbezeichnung. Ein separates Tabellenblatt, das das Joblevel mit Kompetenzen verknüpfte.
„Die Security in meinem Unternehmen wollte mein Tool überprüfen“, erzählte sie der Gruppe. „Ich sagte, es ist in Google Docs gespeichert. Sie meinten nur: 'Oh, so einfach ist das.'“
Einfach – aber Turnmeyer hatte das erst durch das Bauen gelernt. Die Sache, die sie drei Wochen zuvor noch nicht wusste, war, dass es Logging gab – eine Funktion, die den Fortschritt einer Person speichert, sodass das Tool nicht zurückgesetzt wird, wenn man einmal weggeht und zurückkommt.
Ich habe Claude verflucht“, sagte sie, „bis es mir sagte, dass es Logging gibt.
Das ist es, was man beim tatsächlichen Bauen lernt. Nicht das, was man geplant hatte zu lernen, sondern das, von dem man nicht wusste, dass man es wissen musste.
Die Frage darunter
Irgendwann während der Sitzung im Januar kam das Gespräch zur eigentlichen Kernfrage, um die es monatelang gekreist war.
Die Gruppe diskutierte fortwährend über Architektur, Berechtigungen, Speicherung, Dashboards – alles echte Probleme. Aber darunter lag eine grundlegendere Frage: Was wollten sie eigentlich bauen, und für wen?
Das Tool war ursprünglich als Auswahl-Diagnose gedacht – etwas, das eine TA-Führungskraft Kandidat:innen oder Mitarbeitenden senden konnte, um zu prüfen, ob deren tatsächliche Fähigkeiten mit dem Lebenslauf übereinstimmen, und genau dieses Bild sichtbar zu machen, bevor eine Auswahlentscheidung getroffen wurde.
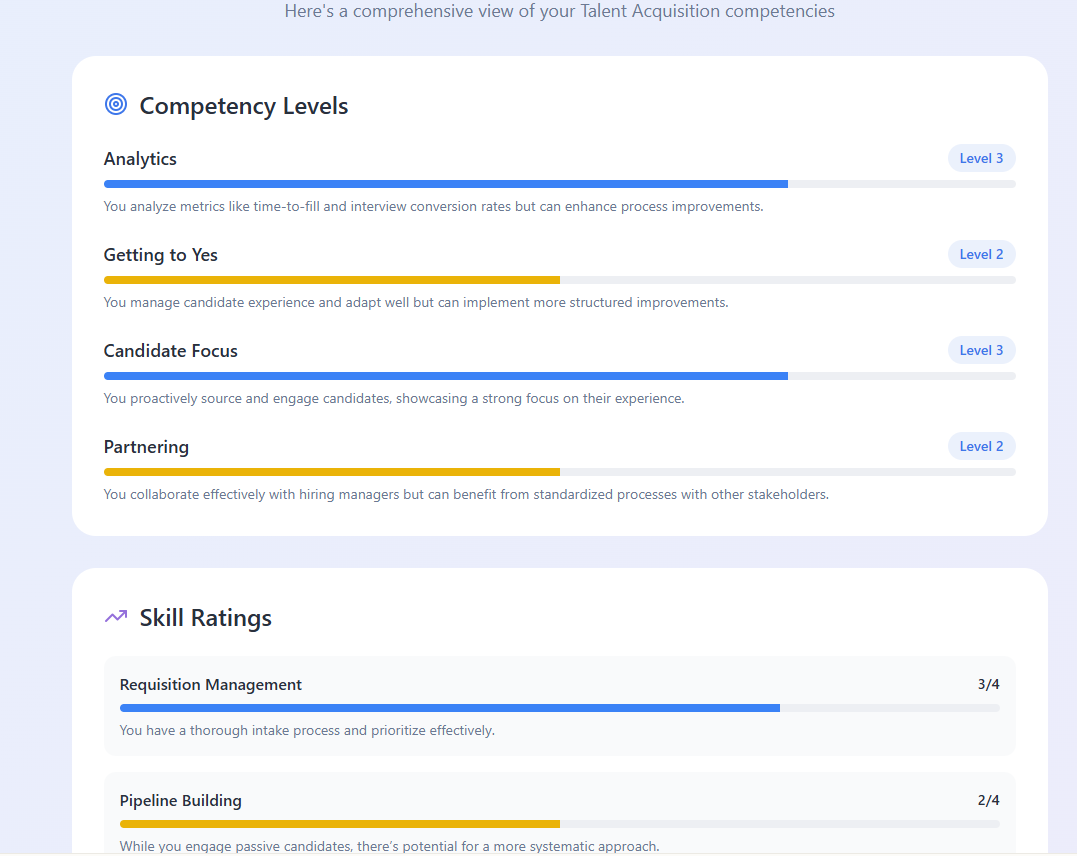
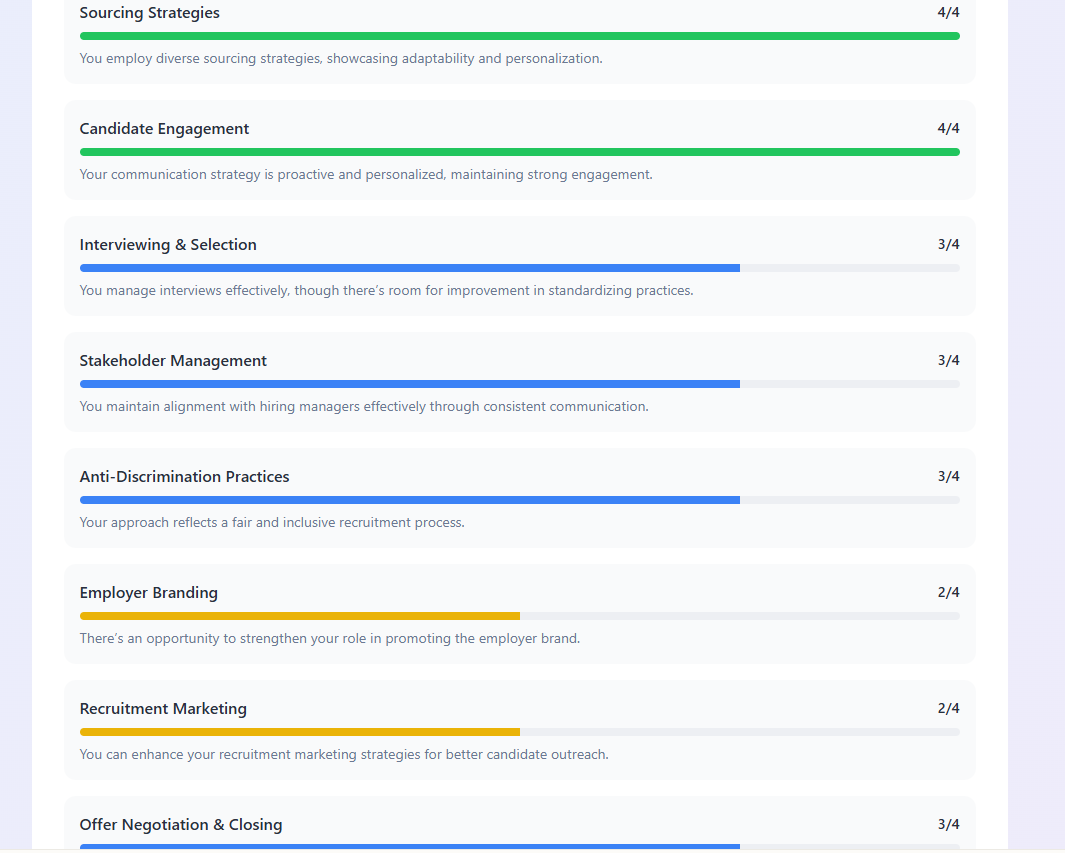

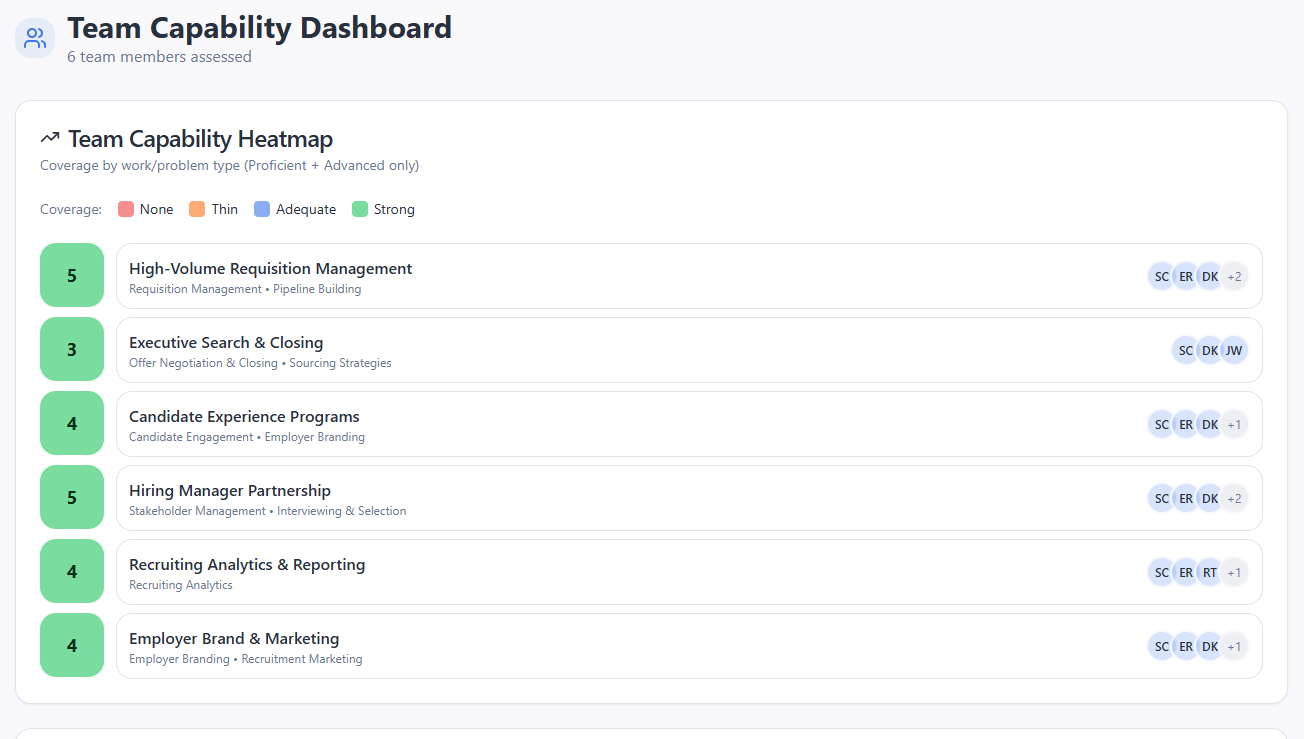
Hier siehst du eine Auswahl von Screenshots der Art von Bericht, die das Tool für Bewerber:innen produzierte. Für die Bewertenden half ein Dashboard der aktuellen Teamstärken dabei, sich darauf zu fokussieren, in welchen Bereichen der/die Bewerber:in bewertet werden soll, um eventuelle TA-Team-Schwächen zu adressieren.
Dieser Kern hatte sich nicht verändert. Aber jede praktische Entscheidung, die sie getroffen hatten – ein Leader-Dashboard hinzufügen, über Abomodelle nachdenken, den Anmeldeprozess gestalten – zog sie in Richtung etwas Komplexerem.
Echtzeit-Dashboards bedeuteten fortlaufenden Zugriff, was wiederum Abogebühren bedeutete – und damit rückte man näher an eine Art von Enterprise-Tooling heran, die sich viele Organisationen kaum leisten oder effektiv betreiben können.
„Wir wollen kein HCM-Anbieter werden“, sagte Satterfield.
Turnmeyer war offen, wo sie stand.
„Mein Ziel war es nur, etwas Neues zu lernen.“
Das war kein Rückzug aus dem Projekt, sondern eine ehrliche Bilanz dessen, was sie schon aus dem Experiment gezogen hatte. Sie hatte Neues gelernt und war bereits dabei, ein neues Performance-Management-Tool zu bauen, in das sie die Erfahrungen aus der Gruppe einfließen ließ.
Sie musste das Gruppentool nicht zum Produkt machen, um einen echten Mehrwert daraus zu ziehen.
In dieser Phase war mein eigenes Interesse hauptsächlich redaktioneller Natur. Ich wollte eine Geschichte erzählen und etwas zum Anschauen bieten – kein Abonnementprodukt, sondern eine Demonstration, die HR-Praktiker:innen inspirieren und vielleicht zum Nachbauen animieren könnte.
Dieser Artikel war Teil davon. Könnte ich einen Download-Guide erstellen? Mit der Zeit vielleicht ein Live-Event, bei dem die Gruppe diskutieren könnte, was sie gebaut haben, das Publikum mit dem Tool zu interagieren ließe und das Ganze als Podcast aufgezeichnet würde? Ich hatte viele Ideen, aber der Spielraum dafür wurde mit den Zielen des neuen Jahres für uns alle immer knapper.
Satterfields Interesse war das kommerziellste – und das machte sie auch klar. Sie hatte vor, das Ganze eines Tages zu einem Produkt zu machen. Sie würde es nicht allein tun. Aber sie war bereit, weiter darauf hinzuarbeiten, dass daraus etwas wird, das eines Tages verkauft werden könnte.
Diese dreifache Divergenz der Absichten – Lernen, Storytelling, Produkt – ist wahrscheinlich in jeder solchen Gruppe angelegt. Das offene Gespräch darüber im Januar war hilfreicher, als so zu tun, als hätten immer alle dasselbe Ziel verfolgt.
Die Demo als Antwort
Die Frage, wie man Menschen das Ausprobieren des Tools ermöglichen könnte, war seit der Einführung des Lebenslauf-Uploads ungelöst im Raum gestanden. Tests mit echten Nutzern sind wertvoll, bringen aber auch eigene Probleme mit sich. Das Tool muss zuverlässig funktionieren, die Nutzer brauchen genug Kontext, um zu verstehen, was sie tun, und ein schlechter erster Eindruck lässt sich nur schwer ausbügeln.
Turnmeyer schlug die einfachste Lösung vor, die die Gruppe je in Betracht gezogen hatte.
Sie hatte sich Demo-Aufzeichnungen angesehen – kurze Rundgänge von ein bis zwei Minuten, die zeigten, wie ein Tool funktioniert, ohne dass der Zuschauer es selbst benutzen muss. Sie schlug vor, dass das vielleicht schon reicht. Die Menschen könnten das Tool in Aktion sehen, verstehen, was es macht und warum, und am Ende das Gefühl haben, dass es möglich ist.
Sie müssten sich nicht einloggen, kein Organigramm bereitstellen oder scheitern, wenn eine Bewertungsfrage nicht zu ihrer Situation passt.
Das Feedback, das ich zu vielen meiner Blogbeiträge bekomme, ist, dass die Leute eigentlich nicht genau das Gleiche kopieren und einfügen wollen. Sie wollen nur wissen, dass sie dazu grundsätzlich in der Lage sind.
Erin Turnmeyer · VP of People Operations
Diese Beobachtung spricht einen wichtigen Punkt an, wie HR-Praktiker derzeit auf KI-Tools reagieren. Die Lücke, die viele von ihnen überbrücken müssen, besteht nicht darin, zu wissen, dass es etwas gibt, und es dann zu nutzen. Es geht darum, überhaupt daran zu glauben, dass sie so etwas selber machen könnten.
Eine Demo, die zeigt, dass Praktiker ihr eigenes Tool bauen, beantwortet eine andere Frage als ein fertiges Produkt – nicht „Ist dieses Tool gut?“, sondern „Könnte jemand wie ich das gemacht haben?“
Die Idee kam gut an. Sie löste die Testprobleme, verringerte die Komplexität beim Teilen eines nicht produktionsreifen Tools und betonte weiterhin das, worauf die Gruppe immer den Fokus legen wollte: den Prozess und das Denken, nicht nur das Ergebnis.
Was das Experiment gezeigt hat: Ein Leitfaden für HR-Gestalter
- Beginne beim Problem, nicht bei der Technologie. Die anfängliche Begeisterung der Gruppe für Sentimentanalyse war echt, lenkte sie aber von einem zugänglicheren, wertvolleren Problem ab. Der Wechsel zum Skill-Mapping funktionierte, weil er mit einem echten Anwendungsfall begann, der bereits in der Praxis getestet worden war.
- Maßgeschneidert schlägt generisch. Jeder Teilnehmer hat die Grenzen von Unternehmens-HR-Plattformen erlebt. Die auf spezifische Kontexte zugeschnittenen Tools – Turnmeyers Benefit-Empfehlungsgeber, Satterfields Heatmap – waren den Standardlösungen überlegen. Die Argumente, eigene Lösungen zu bauen, sind stärker denn je, die Hürden niedriger.
- Das Gegenprüfen ist das ganze Spiel. Selbsteinschätzungen sind immer nur so gut wie die Selbstkenntnis der Menschen – und die ist bekanntlich oft unzuverlässig. Der wahre Wert eines Tools liegt darin, zu hinterfragen, herauszufordern und sanft zu kalibrieren – nicht nur darin, aufzunehmen, was Menschen über sich glauben.
- Minimum Valuable statt Minimum Viable. Wenn die erste Version dem Nutzer keinen Grund gibt, zurückzukehren, ist der Fahrplan egal. Gestalte für den ersten Eindruck, nicht für den fünften.
- Buy-in ist strukturell, nicht weich. Die Frage, ob die KI das finale Rating vergibt oder der Nutzer es bestätigt, ist kein UX-Detail. Sie entscheidet, ob das Tool Autorität oder Mitgestalter ist – und diese Unterscheidung prägt alles, wie es angenommen und genutzt wird.
- Schneide bereits gebaute Features raus. Die Logik der versunkenen Kosten führt dazu, dass Teams an Dingen weiterarbeiten, in die sie investiert haben, auch wenn diese keinen Mehrwert mehr bieten. Wenn du nicht klar formulieren kannst, wofür ein Feature da ist, hast du deine Antwort. Es zu streichen ist Produktdisziplin, kein Scheitern.
- Teste gegnerisch und früh. Suche gezielt nach Menschen, die dir sagen werden, dass das Tool schlecht ist. Gib ihm den schlimmsten denkbaren Input und sieh, was passiert. Baue die Randfälle ein, bevor du die Standards polierst. Die Glaubwürdigkeit des Tools bemisst sich daran, wie es mit Situationen umgeht, für die es nicht gedacht war.
- Das Tool muss sich das Recht zur Bewertung verdienen. Schon zu bewerten, bevor genug Fragen gestellt sind, ist Anmaßung, keine Effizienz. Klarstellende Rückfragen machen eine Bewertung verteidigungsfähig – und diese Verteidigungsfähigkeit sorgt dafür, dass Feedback wirkt.
- Sprich offen über die Beweggründe aller Beteiligten. Unterschiedliche Absichten in einer Gruppe sind kein Problem, das man managen muss – sie liefern wichtige Informationen. Sie früh zu besprechen, erspart, dass auf ein Ziel hingearbeitet wird, das nur manche wirklich teilen.
- Die schwierigsten Gespräche sind die wichtigsten. Die Gruppe entwickelte ein Tool, um HR-Skills zu beurteilen, und führte dabei eines der ehrlichsten Gespräche über die eigenen Grenzen, an das sich jemand erinnern konnte. Diese Unterhaltung – über rückwärtsgerichtete Frameworks und die Lücke zwischen Prüfungswissen und situativem Urteilsvermögen – war das Produkt genauso wie das Tool selbst.
Die Sitzungen, die als vier Termine geplant waren, zogen sich durch den Winter und ins neue Jahr. Der Prototyp entwickelte sich weiter. Die Absichten der Menschen, die ihn gebaut hatten, waren klarer geworden, ließen sich aber nicht restlos auflösen.
Satterfield baute weiterhin. Turnmeyer hatte das, was sie gelernt hatte, woanders angewendet. Gillies hatte die Gruppe dazu gebracht, disziplinierter darüber nachzudenken, was das Werkzeug eigentlich tun sollte. Ich schrieb die Geschichte von alledem.
Turnmeyer hatte zu Beginn des Prozesses etwas gesagt, das sich als wahr erwies: Sie baute nicht, weil sie dazu aufgefordert wurde, sondern weil sie es verstehen wollte.
Dieses Verständnis darüber, was KI-Werkzeuge tatsächlich tun, worin sie sich irren und was es braucht, um sie nützlich zu machen, war in keiner Konferenzsitzung oder Anbietervorführung verfügbar. Es entstand aus den Entscheidungen, die die Gruppe traf, den Funktionen, die sie strichen, den Momenten, in denen das Werkzeug jemanden falsch einschätzte und sie herausfinden mussten, warum.
Das Nützlichste, was der Jahrgang hervorbrachte, befand sich nicht im Prototyp. Es lag in der dahinterstehenden Überlegung.